Υλικό και Λογισμικό Ι
Διομήδης Σπινέλλης
Τμήμα Διοικητικής Επιστήμης και Τεχνολογίας
Οικονομικό Πανεπιστήμιο Αθηνών
dds@aueb.gr
Εισαγωγή
Καλώς ήρθατε
Υλικό και Λογισμικό Ι
Τι περιλαμβάνει το μάθημα
- Εισαγωγή
- Προγραμματισμός σε επίπεδο μηχανής
- Αυτόματα
- Γραμματικές
- Λεκτική ανάλυση
- Το μεταεργαλείο lex
- Συντακτική ανάλυση
- Το μεταεργαλείο yacc
- Πίνακες συμβόλων
- Διερμηνευτές
- Σημασιολογική ανάλυση
- Παραγωγή ενδιάμεσου κώδικα
- Βελτιστοποίηση κώδικα
- Παραγωγή τελικού κώδικα
Οι σημειώσεις
Το χάσμα υλικού και λογισμικού
Οι δυνατότητες που προσφέρει το υλικό και το λογισμικό έρχονται συχνά
σε αντίθεση ή αλληλοσυμπληρώνονται.
Μερικά καθοριστικά χαρακτηριστικά είναι τα παρακάτω:
- ευκαμψία (flexibility)
Το λογισμικό είναι πιο εύκαμπτο και εύπλαστο από το υλικό.
- απόδοση (performance)
Ένας αλγόριθμος υλοποιημένος σε υλικό μπορεί να είναι ταχύτερος από τον
αντίστοιχο υλοποιημένο σε λογισμικό.
- κόστος (cost)
Το οριακό κόστος αναπαραγωγής του λογισμικού είναι, σε αντίθεση με αυτό του
υλικού, μηδενικό.
Από την άλλη πλευρά σε διαμορφωμένα εμπορικά συστήματα το κόστος του
λογισμικού μπορεί να υπερβαίνει αυτό του υλικού.
Οι γλώσσες προγραμματισμού και τα λειτουργικά συστήματα είναι δύο τεχνολογίες
που επιτρέπουν τη βέλτιστη συνύπαρξη του υλικού με το λογισμικό.
Υλοποίηση γλωσσών προγραμματισμού
Μια γλώσσα προγραμματισμού μπορεί - ανάλογα με τη γλώσσα -
να υλοποιηθεί με τους παρακάτω τρόπους:
- από υλικό
(π.χ. επεξεργαστές που προγραμματίζονται κατευθείαν στη γλώσσα FORTH)
- με ένα συμβολομεταφραστή (assembler)
(προγραμματισμός σε συμβολικές γλώσσες)
- με ένα διερμηνευτή (interpreter)
(συνήθως σε συνδυασμό με κάποια στάδια μεταγλώττισης για γλώσσες
πολύ υψηλού επιπέδου όπως Prolog, Lisp, Haskell, ML, Basic, Perl, Python,
TCL, sh, csh, awk)
- με ένα μεταγλωττιστή (compiler)
(τυπικά για γλώσσες τρίτης γενιάς όπως Pascal, FORTRAN, Ada, C, C++)
καθώς και με συνδυασμούς τους.
Ο ορισμός ενός μεταγλωττιστή
Ένας μεταγλωττιστής ορίζεται από:
- την αρχική γλώσσα (Α)
- την τελική γλώσσα (Τ)
- τη γλώσσα υλοποίησης (Υ)
Ο συνδυασμός αυτός παριστάνεται από ένα διάγραμμα Τ (T diagram)
όπως το παρακάτω:
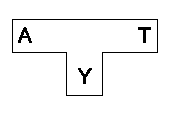
Ο ίδιος συνδυασμός για ένα μεταγλωττιστή Μ συμβολίζεται και ως
MATY.
Τελικός κώδικας
Ο τελικός κώδικας που παράγεται από έναν μεταγλωττιστή μπορεί να είναι:
- συμβολική γλώσσα ενός συγκεκριμένου επεξεργαστή
- γλώσσα μηχανής ενός συγκεκριμένου επεξεργαστή
- γλώσσα μιας ιδεατής μηχανής (virtual machine)
- μια άλλη γλώσσα χαμηλότερου επιπέδου (π.χ. C για ένα μεταγλωττιστή C++)
- μια δομή δεδομένων η οποία θα εκτελεστεί από ένα διερμηνευτή
Παραδείγματα
Τα παρακάτω παραδείγματα έχουν ως είσοδο το πρόγραμμα που τυπώνει "hello, world".
Συμβολική γλώσσα Linux Intel 386
.file "hello.c"
.version "01.01"
gcc2_compiled.:
.section .rodata
.LC0:
.string "hello, world\n"
.text
.align 4
.globl main
.type main,@function
main:
pushl %ebp
movl %esp,%ebp
pushl $.LC0
call printf
addl $4,%esp
.L1:
leave
ret
.Lfe1:
.size main,.Lfe1-main
.ident "GCC: (GNU) egcs-2.91.66 19990314/Linux (egcs-1.1.2 release)"
Γλώσσα μηχανής από δυαδικό αρχείο Linux Intel 386 σε μορφή δεκαεξαδική και ASCII
hello.o: file format elf32-i386
Contents of section .text:
0000 5589e568 00000000 e8fcffff ff83c404 U..h............
0010 c9c3 ..
Contents of section .data:
Contents of section .note:
0000 08000000 00000000 01000000 30312e30 ............01.0
0010 31000000 1...
Contents of section .rodata:
0000 68656c6c 6f2c2077 6f726c64 0a00 hello, world..
Contents of section .comment:
0000 00474343 3a202847 4e552920 65676373 .GCC: (GNU) egcs
0010 2d322e39 312e3636 20313939 39303331 -2.91.66 1999031
0020 342f4c69 6e757820 28656763 732d312e 4/Linux (egcs-1.
0030 312e3220 72656c65 61736529 00 1.2 release).
Συμβολική γλώσσα της ιδεατής μηχανής Java Virtual Machine
Compiled from hello.java
class hello extends java.lang.Object {
hello();
public static void main(java.lang.String[]);
}
Method hello()
0 aload_0
1 invokespecial #9 <Method java.lang.Object()>
4 return
Method void main(java.lang.String[])
0 getstatic #12 <Field java.io.PrintStream out>
3 ldc #2 <String "Hello ">
5 invokevirtual #13 <Method void print(java.lang.String)>
8 getstatic #12 <Field java.io.PrintStream out>
11 new #7 <Class java.lang.StringBuffer>
14 dup
15 aload_0
16 iconst_0
17 aaload
18 invokestatic #16 <Method java.lang.String valueOf(java.lang.Object)>
21 invokespecial #10 <Method java.lang.StringBuffer(java.lang.String)>
24 ldc #1 <String " ">
26 invokevirtual #11 <Method java.lang.StringBuffer append(java.lang.String)>
29 aload_0
30 iconst_1
31 aaload
32 invokevirtual #11 <Method java.lang.StringBuffer append(java.lang.String)>
35 invokevirtual #15 <Method java.lang.String toString()>
38 invokevirtual #14 <Method void println(java.lang.String)>
41 return
Απαιτήσεις
Ο σχεδιασμός και η υλοποίηση ενός μεταγλωττιστή ή ενός διερμηνευτή
(και συχνά και μιας γλώσσας προγραμματισμού)
έχουν ως στόχο να ικανοποιήσουν τις παρακάτω,
συχνά αντικρουόμενες, απαιτήσεις:
- αποδοτικότητα του παραγόμενου κώδικα σε ταχύτητα και οικονομία στη μνήμη
που καταλαμβάνει
- ταχύτητα εκτέλεσης
- διαγνωστικά μηνύματα
- ανάνηψη από λάθη
- αξιοπιστία
- μεταφερσιμότητα ως προς την αρχική και τελική γλώσσα καθώς και ως προς
το περιβάλλον υλοποίησης
- σύνδεση με ολοκληρωμένα περιβάλλοντα ανάπτυξης
Σχεδίαση
Η διεργασία της μεταγλώττισης μπορεί να διαχωριστεί στις παρακάτω
ξεχωριστές λειτουργίες οι οποίες εκτελούνται σε διαδοχικές φάσεις:
Επιπλέον, οι παρακάτω δύο λειτουργίες υποστηρίζουν όλες τις φάσεις της
διεργασίας:
Βιβλιογραφία
Γενική βιβλιογραφία
- Harold Abelson,
Gerald Jay Sussman, and Jullie Sussman.
Structure and Interpretation of Computer Programs.
MIT Press, 1990.
- Alfred V. Aho, Ravi Sethi,
and Jeffrey D. Ullman.
Compilers, Principles, Techniques, and Tools.
Addison-Wesley, 1985.
- Keith Clarke.
One-pass code generation using continuations.
Software: Practice & Experience, 19(12):1175–1192, December
1989.
- Jack W. Davidson
and David B. Whalley.
Quick compilers using peephole optimization.
Software: Practice & Experience, 19(1):79–97, January 1989.
- John M. Dedourek,
Uday G. Gujar, and Marion E. McIntyre.
Scanner design.
Software: Practice & Experience, 10:959–972, 1980.
- H. Dobler and
K. Pirklbauer.
Coco-2: A new compiler compiler.
ACM SIGPLAN Notices, 25(5):82–90, May 1990.
- Charles N. Fischer
and Richard J. Jr. Leblanc.
Crafting a Compiler With C.
Addison-Wesley, 1991.
- Robert W. Gray, Vincent P.
Heuring, Steven P. Levi, Anthony M. Sloane, and William M. Waite.
Eli: A complete, flexible compiler construction system.
Communications of the ACM, 35(2):121–131, February 1992.
- J. Grosch and
H. Emmelmann.
A tool box for compiler construction.
In D. Hammer, editor, Compiler Compilers : Third International Workshop,
CC '90, pages 106–116, Schwerin, Germany, October 1991.
Springer-Verlag.
Lecture Notes in Computer Science 477.
- J. Grosh.
Ast — a generator for abstract syntax trees.
Compiler Generation Report 15, GMD Forshungsstelle an der Universität
Karlsruhe, Germany, August 1989.
(Revised Version).
- Stephen C. Johnson.
Yacc — yet another compiler-compiler.
Computer Science Technical Report 32, Bell Laboratories, Murray Hill, NJ, USA,
July 1975.
- Stephen C. Johnson.
A tour through the portable C compiler.
Bell Telephone Laboratories, Murray Hill, NJ, USA (also available online
http://plan9.bell-labs.com/7thEdMan/), seventh edition, 1979.
- Brian W. Kernighan
and Rob Pike.
The
UNIX Programming Environment.
Prentice-Hall, 1984.
- Michael E. Lesk.
Lex — a lexical analyzer generator.
Computer Science Technical Report 39, Bell Laboratories, Murray Hill, NJ, USA,
October 1975.
- B. J. McKenzie.
Fast peephole optimization techniques.
Software: Practice & Experience, 19(12):1151–1162, December
1989.
- Frank G. Pagan.
Converting interpreters into compilers.
Software: Practice & Experience, 18(6):509–527, June 1988.
- Dennis M. Ritchie.
A tour through the UNIX C compiler.
In UNIX Programmer's Manual. Volume 2 — Supplementary
Documents.
- Peter H. Salus, editor.
Handbook of Programming Languages, volume III: Little Languages and
Tools.
Macmillan Technical Publishing, 1998.
- Ravi Sethi.
Programming Languages: Convepts and Constructs.
Addison-Wesley, 1989.
- Andrew S. Tanenbaum,
M. Frans Kaashoek, Koen G. Langendoen, and Ceriel J. H. Jacobs.
The design of very fast portable compilers.
ACM SIGPLAN Notices, 24(11):125–131, November 1989.
- Ken Thompson.
A new C compiler.
In Proceedings of the Summer 1990 UKUUG Conference, pages
41–51, London, UK, July 1990. UKUUG.
- David H. D. Warren.
Logic programming and compiler writing.
Software: Practice & Experience, 10:97–125, 1980.
Ασκήσεις
Άσκηση 1 (προαιρετική)
- Αναλύστε πως διαφορετικές τεχνικές υλοποίησης γλωσσών προγραμματισμού επηρεάζουν
της απαιτήσεις που έχουμε από τα αντίστοιχα εργαλεία.
Παράδειγμα:
Η υλοποίηση μιας γλώσσας με μεταγλωττιστή επηρεάζει ... την αποδοτικότητα
του παραγώμενου κώδικα σε ταχύτητα διότι ...
Προγραμματισμός σε επίπεδο μηχανής
Δομή ενός υπολογιστή
Κεντρική μονάδα επεξεργασίας
O κύκλος εντολών
- Ανάκληση εντολής (Instruction fetch)
- ΚΔιΜ <- ΜΠ
- ΚΕ <- Μνήμη[ΚΔιΜ]
- Αποκωδικοποίηση εντολής (Instruction decode)
- Α <- ΓΚ1
- Β <- ΓΚ2
- ΜΕ <- ΜΕ + 1
- Εκτέλεση εντολής (Instruction execution)
- ΚΔιΜ <- Α + ΚΕ, ΚΔεΜ <- ΓΚι (για εντολές πρόσβασης στη μνήμη)
- Γ <- Α * Β (για αριθμητικές εντολές)
- Γ <- ΜΠ + ΚΕ (έλεγχος τιμής από ΜΑΛ) (για εντολές διακλάδωσης)
- Πρόσβαση μνήμης (Memory access)
- ΚΔεΜ <- Μ[ΚΔιΜ] ή Μ[ΚΔιΜ] <- ΚΔεΜ
- ΜΠ <- Γ (για εντολές διακλάδωσης)
- Γ <- ΜΠ + ΚΕ (έλεγχος τιμής από ΜΑΛ)
- Εγγραφή
Οικογένειες επεξεργαστών
- Χαρακτηριστικά ενός επεξεργαστή
- Αρχικοί επεξεργαστές
- Οικογένειες επεξεργαστών
- IBM 360
- CDC 6600
- Digital PDP-11, VAX, Alpha
- Intel 4004, 8008, 8080, 8086
- Motorola 68000
- MIPS
- SPARC
- Power PC
Η οικογένεια επεξεργαστών iAPX86
- 8080 (8 bit, ο πρόγονος)
- 8086/8088 (16 bit)
- 80286 (24 bit, προστατευμένος ρυθμός)
- 80386 (32 bit, ιδεατή μνήμη)
- 80486 (απόδοση, μαθηματικός επεξεργαστής)
- Pentium (παράλληλη εκτέλεση εντολών)
- Pentium MMX (εκτέλεση πολλαπλών ακέραιων δεδομένων)
- Pentium II (δυναμική εκτέλεση εντολών, διπλός δίαυλος)
- Pentium III (εκτέλεση πολλαπλών δεδομένων κινητής υποδιαστολής)
Καταχωρητές
- Το μοντέλο καταχωρητών ειδικής χρήσης
- Καταχωρητές δεδομένων
- EAX (AX (AH/AL)): Συσσωρευτής (Accumulator)
- EBX (BX (BH/BL)): Βάση μνήμης
- ECX (DX (CH/CL)): Μετρητής
- EDX (DX (DH/DL)): Πολλαπλασιασμός, διαίρεση
- Καταχωρητές διευθύνσεων
- SP: (stack pointer) Δείκτης στοίβας (Stack pointer)
- BP: (base pointer) Βάση μνήμης
- SI: (source index) Δείκτης προέλευσης
- DI: (desination index) Δείκτης προορισμού
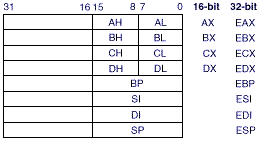
- Καταχωρητές τμημάτων μνήμης
- CS: (code segment) Τμήμα εντολών
- DS: (data segment) Τμήμα δεδομένων
- SS: (stack segment) Τμήμα στοίβας
- ES: (extra segment) Πρόσθετο τμήμα
- FS: (extra segment) Πρόσθετο τμήμα
- GS: (extra segment) Πρόσθετο τμήμα
- Καταχωρητές ελέγχου
Προσδιορισμός τελεστέων
Σημείωση
Η σύνταξη που χρησιμοποιούμε είναι αυτή των συμβολομεταφραστών της
AT&T που υποστηρίζονται στο λειτουργικό σύστημα Unix (π.χ. GNU as).
Η σύνταξη αυτή διαφέρει σημαντικά από αυτή που χρησιμοποιεί η Intel.
Το μέγεθος του τελεστή ορίζεται από το τελευταίο γράμμα της εντολής:
- l
- long (4 byte, long ή int)
- w
- word (2 byte, short)
- b
- byte (1 byte, char)
Συνδιασμοί τελεστών:
- Καταχωρητής, Καταχωρητής (π.χ. addl %eax, %eax)
- 'Αμεσος, Καταχωρητής (π.χ. subl $3, %ecx)
- Μνήμη, Καταχωρητής (π.χ. addl 54(%esi), %ax)
- 'Αμεσος, Μνήμη (π.χ. movl $45, 12(%ebp, %esi))
Παράσταση εντολών
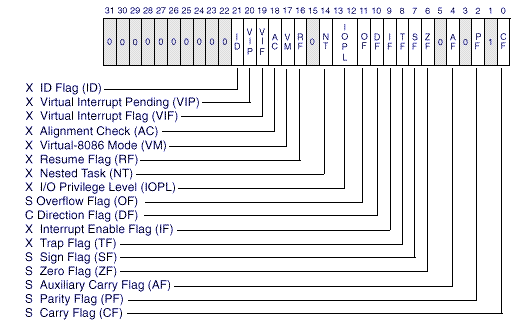
Ενδείκτης διακλάδωσης
- CF:
- (Carry flag)
Κρατούμενο (Carry):
1 αν η πράξη δημιούργησε κρατούμενο.
- ZF:
- (Zero flag)
Μηδέν:
1 αν το αποτέλεσμα της πράξης είναι 0.
- SF:
- (Sign flag)
Πρόσημο (sign)
1 αν το αποτέλεσμα είναι αρνητικός αριθμός.
- PF:
- (Parity flag)
Ισοτιμία
1 αν το αποτέλεσμα έχει μονό αριθμό από bit που είναι 1.
- OF:
- (Overflow flag)
Υπερχείλιση:
1 αν το αποτέλεσμα δε μπορεί να παρασταθεί ως θετικός η αρνητικός αριθμός.
Εντολές μεταφοράς δεδομένων
- mov πηγή, προορισμός
- (Move)
Μεταφορά
πηγή -> προορισμό
- push πηγή
- Μεταφορά στη στοίβα
%esp <- %esp - $4
(%esp) <- πηγή
- pop προορισμός
- Μεταφορά από τη στοίβα
προορισμός <- (%esp)
%esp <- %esp + $4
- xchg προορισμός, πηγή
- (Exchange)
Εναλλαγή
προορισμός <- πηγή
πηγή <- προορισμός
(ταυτόχρονα)
Αριθμητικές εντολές
- add πηγή, προορισμός
- (Add)
Πρόσθεση
προορισμός <- προορισμός + πηγή
- inc προορισμός
- (Increment)
Αύξηση κατά ένα
προορισμός <- προορισμός + 1
- sub πηγή, προορισμός
- (Subtract)
Αφαίρεση
προορισμός <- προορισμός - πηγή
- dec προορισμός
- (Decrement)
Μείωση κατά ένα
προορισμός <- προορισμός - 1
- neg προορισμός
- (Negate)
Αλλαγή προσήμου
προορισμός <- - προορισμός
- cmp πηγή, προορισμός
- (Compare)
Σύγκριση
Εκτελείται η πράξη προορισμός - πηγή και ενημερώνονται οι ενδείκτες
διακλάδωσης.
- mul πηγή
- (Multiply)
Πολλαπλασιασμός
%edx:%eax <- %eax * πηγή
- div πηγή
- (Divide)
Διαίρεση
%eax <- %edx:%eax / πηγή
%edx <- %edx:%eax mod πηγή
Για να μετατρέψουμε τον ακέραιο 32 bit στον καταχωρητή %eax σε
ακέραιο διαιρετέο 64 bit στο ζευγάρι καταχωρητών %edx:%eax
(όπως απαιτεί η div) χρησιμοποιούμε την εντολή cltd (χωρίς παραμέτρους)
(convert long to double long).
Εντολές δυαδικών ψηφίων
- and πηγή, προορισμός
- Σύζευξη
προορισμός <- προορισμός & πηγή
- or πηγή, προορισμός
- Διάζευξη
προορισμός <- προορισμός | πηγή
- xor πηγή, προορισμός
- Αποκλειστική διάζευξη
προορισμός <- προορισμός ^ πηγή
- not προορισμός
- Αντιστροφή
προορισμός <- ~ προορισμός
- test πηγή, προορισμός
- Έλεγχος
- shl αριθμός, προορισμός
- (Shift left)
Ολίσθηση (Shift) αριστερά
προορισμός <- προορισμός << πηγή
- shr αριθμός, προορισμός
- (Shift right)
Ολίσθηση δεξιά
προορισμός <- προορισμός >> πηγή
- sar αριθμός, προορισμός
- (Shift arithmetic right)
Αριθμητική ολίσθηση δεξιά
προορισμός <- προορισμός >> πηγή
- rol αριθμός, προορισμός
- (Rotate left)
Περιστροφή αριστερά
- ror αριθμός, προορισμός
- (Rotate right)
Περιστροφή δεξιά
Εντολές άλματος
- JMP προορισμός
- Άλμα
- CALL προορισμός
- Κλήση
- RET
- (Return)
Επιστροφή
- JA/JNBE προορισμός
- (Jump above)
Άλμα αν μεγαλύτερο (χωρίς πρόσημο)
- JAE/JNB προορισμός
- (Jump above or equal)
Άλμα αν μεγαλύτερο ή ίσο (χωρίς πρόσημο)
- JB/JNAE προορισμός
- (Jump bellow)
Άλμα αν μικρότερο (χωρίς πρόσημο)
- JBE/JNA προορισμός
- (Jump below or equal)
Άλμα αν μικρότερο ή ίσο (χωρίς πρόσημο)
- JC προορισμός
- (Jump carry)
Άλμα αν κρατούμενο
- JNC προορισμός
- (Jump no carry)
Άλμα αν όχι κρατούμενο
- JE/JZ προορισμός
- (Jump equal)
Άλμα αν ίσο
- JNE/JNZ προορισμός
- (Jump not equal)
Άλμα αν όχι ίσο
- JG/JNLE προορισμός
- (Jump greater)
Άλμα αν μεγαλύτερο (με πρόσημο)
- JGE/JNL προορισμός
- (Jump greater or equal)
Άλμα αν μεγαλύτερο ή ίσο (με πρόσημο)
- JL/JNGE προορισμός
- (Jump less)
Άλμα αν μικρότερο (με πρόσημο)
- JLE/JNG προορισμός
- (Jump less or equal)
Άλμα αν μικρότερο ή ίσο (με πρόσημο)
- JO προορισμός
- (Jump overflow)
Άλμα αν υπερχείλιση
- JNO προορισμός
- (Jump no overflow)
Άλμα αν όχι υπερχείλιση
- JS προορισμός
- (Jump sign)
Άλμα αν πρόσημο
- JNS προορισμός
- (Jump no sign)
Άλμα αν όχι πρόσημο
Βιβλιογραφία
- Alfred V. Aho, Ravi Sethi,
and Jeffrey D. Ullman.
Compilers, Principles, Techniques, and Tools, pages 519–520.
Addison-Wesley, 1985.
- Free Software Foundation.
Using as, 1999.
http://www.gnu.org/manual/gas-2.9.1/.
- John L. Hennessy
and David A. Patterson.
Computer Architecture: A Quantitative Approach.
Morgan Kaufmann Publishers, second edition, 1996.
- Intel Corporation.
The
Intel Architecture Software Developer's Manual, Volume 1: Basic
Architecture, 1999.
http://www.intel.com/design/PentiumII/manuals/243190.htm.
- Intel Corporation.
Intel
Architecture Software Developer's Manual, Volume 2: Instruction Set Reference
Manual, 1999.
http://www.intel.com/design/PentiumII/manuals/243190.htm.
Ασκήσεις
- Γράψτε σε συμβολική γλώσσα σειρά εντολών που να θέτουν τις διευθύνσεις
από 1000 - 2000 σε 0.
- Γράψτε σε συμβολική γλώσσα σειρά εντολών που να αποθηκεύουν στις
διευθύνσεις από 1000 - 1200 τους άρτιους αριθμούς από 0 - 400.
- Γράψτε σε συμβολική γλώσσα σειρά εντολών που να μεταφέρουν τα
περιεχόμενα των διευθύνσεων από 1000 - 2000 στην περιοχή 4000.
- Υπολογίστε πόσες εντολές θα εκτελεστούν για την παραπάνω διαδικασία.
- Αν ο υπολογιστής εργάζεται με ρολόι 133MHz και εκτελεί μια εντολή
κάθε δύο κύκλους σε πόσο χρόνο θα εκτελεστεί η παραπάνω διαδικασία;
Συμβολική γλώσσα και η εκτέλεση γλωσσών υψηλού επιπέδου
Λειτουργίες του συμβολομεταφραστή
- Χρήση συμβολικών εντολών
- Χρήση συμβολικών τελεστέων
- Αυτόματη ανάθεση διευθύνσεων
- Δημιουργία αρχείων συνδέτη
- Σχόλια
- Υπολογισμός σταθερών
Δομή του πηγαίου κώδικα
- Ο πηγαίος κώδικας της συμβολικής γλώσσας είναι δομημένος με βάση ξεχωριστές
γραμμές κώδικα.
- Κάθε γραμμή μπορεί να περιέχει μία και μόνο μία εντολή.
- Οι εντολές δεν απαιτείται να τερματίζονται με κάποιον ειδικό χαρακτήρα.
- Τα σχόλια γράφονται με τη μορφή της C++:
// This is a comment
- Ο συμβολομεταφραστής δέχεται και ειδικές εντολές. Αυτές αρχίζουν
πάντα με μια τελεία:
.text
- Οι εντολές χωρίζονται από τις παραμέτρους και τους τελεστέους με κενά.
- Οι τελεστέοι χωρίζονται μεταξύ τους με κόμμα.
Παράδειγμα:
cmp $10,%ebx
je end
push %ebx
mov %ebx, %esi
inc %esi
push $intform
Προσδιορισμός σταθερών
Στη συμβολική γλώσσα εκτός από εντολές του επεξεργαστή χρειάζεται
να παραστήσουμε και σταθερές.
Μπορούμε να εισάγουμε:
- ακέραιους στο δεκαδικό σύστημα (π.χ. 10, 454, 23)
- ακέραιους στο δεκαεξαδικό (hexadecimal)
σύστημα αρχίζοντάς τους με 0x (π.χ. 0x5e, 0x34, 0xa23f)
- χαρακτήρες αρχίζοντάς τους με ένα μονό εισαγωγικό (π.χ. 'a, '4, '\n)
Μπορούμε να συνδυάσουμε σταθερές με τελεστές με σημασιολογία ίδια με
αυτή της C.
Μοναδιαίοι (unary) τελεστές:
Δυαδικοί (binary) τελεστές:
- Μέγιστη προτεραιότητα
- Ενδιάμεση προτεραιότητα
- Ελάχιστη προτεραιότητα
Η εισαγωγή των σταθερών στη μνήμη γίνεται με εντολές του συμβολομεταφραστή:
-
Στο συμβολομεταφραστή gas οι σταθερές εισάγονται με τις παρακάτω
εντολές:
- .byte
- Εισαγωγή σταθερών με μήκος 1 byte
- .short
- Εισαγωγή σταθερών με μήκος 2 byte
- .word
- Εισαγωγή σταθερών με μήκος 4 byte
- .string
- Εισαγωγή συμβολοσειρών
- Μετά από κάθε εντολή μπορούν να γραφούν μια ή περισσότερες σταθερές
χωρισμένες με κόμμα.
Παράδειγμα:
.byte 'a', 'b'
.short 578
.word 324234
.string "hello, world\n"
Χρήση συμβόλων
- Σε αρχεία πηγαίου κώδικα του συμβολομεταφραστή μπορούμε να αναφερθούμε με
συμβολικό τρόπο σε διευθύνσεις μνήμης (memory addresses)
δεδομένων ή κώδικα.
- Ο κώδικας και τα δεδομένα που γράφουμε καταχωρούνται σε αυξανόμενες
διευθύνσεις μνήμης.
- Μπορούμε να αποδώσουμε την τρέχουσα διεύθυνση μνήμης σε μια συμβολική
σταθερά (ετικέτα (label)))
γράφοντας στην αρχή της γραμμής το όνομα της σταθεράς (σύμφωνα με τους
κανόνες ονομασίας μεταβλητών της C) ακολουθούμενο από μια άνω κάτω τελεία:
thisaddress:
Παράδειγμα:
intform: .string "%d\n"
.globl main
main:
mov $0, %ebx
loop:
cmp $10,%ebx
Το περιβάλλον εκτέλεσης της C
Για να τους σκοπούς του μαθήματος τα προγράμματα σε συμβολική γλώσσα θα
γράφονται και θα συνδέονται στο περιβάλλον εκτέλεσης των προγραμμάτων της
C.
Αυτό μας δίνει τις παρακάτω δυνατότητες:
- Έναρξη του προγράμματος από την ετικέτα main
- Κλήσεις των συναρτήσεων της βιβλιοθήκης της C με την εντολή call.
- Τερματισμός του προγράμματος με κλήση της συνάρτησης exit.
Παράδειγμα:
hi: .string "hello, world\n"
.globl main
main:
push $hi
call printf
addl $5, %sp
pushl $0
call exit
Κλήση συναρτήσεων
- Η κλήση των συναρτήσεων της C γίνεται τοποθετώντας τις παραμέτρους
τις συνάρτησης από δεξιά προς τα αριστερά στη στοίβα (με την εντολή push).
- Κατά την επιστροφή από τη συνάρτηση ο δείκτης της στοίβας (%sp)
πρέπει να λάβει την αρχική του τιμή με τη χρήση της εντολής
addl $N, %sp όπου N ο αριθμός των byte που είχαν προστεθεί στη στοίβα.
- Η τιμή που επιστρέφει μια συνάρτηση βρίσκεται στον καταχωρητή %eax.
Χρήση καταχωρητών
Στο περιβάλλον λειτουργίας της C τα προγράμματα σε συμβολική γλώσσα
πρέπει να χρησιμοποιούν τους καταχωρητές με συγκεκριμένο τρόπο:
Ένα ολοκληρωμένο πρόγραμμα
Το παρακάτω πρόγραμμα αντιγράφει την είσοδό του στην έξοδο μέχρι να
συναντήσει τέλος του αρχείου (τη σταθερά -1).
// Copy standard input to standard output until EOF is read
.globl main
main: // Entry point
loop: call getchar // Read a character in %eax
cmpl $-1, %eax // EOF
je end // Yes, finish
push %eax // Pass it on
call putchar // Print character pushed
addl $4, %esp // Adjust back stack
jmp loop
end: pushl $0 // Exit code
call exit
Βιβλιογραφία
- Free Software Foundation.
Using as, 1999.
http://www.gnu.org/manual/gas-2.9.1/.
Εργαλεία προγραμματισμού στο Unix
Σύνδεση με τον υπολογιστή
- Είσοδος: Start - Run - telnet athena.math.aegean.gr
- Αλλαγή της συνθηματικής σας λέξης (passwd)
- Ειδικοί χαρακτήρες:
| Διαγραφή χαρακτήρα |
control-H ή control-? |
| Διαγραφή γραμμής |
control-U |
| Παύση της εξόδου |
control-S |
| Συνέχιση της εξόδου |
control-Q |
| Τέλος του αρχείου |
control-D |
| Διακοπή |
control-C |
| Προσωρινή διακοπή |
control-Z |
- Έξοδος: logout
Απλές εντολές
| date | Τυπώνει τη μέρα και την ώρα |
| whoami | Τυπώνει το όνομά μας |
| cal | Τυπώνει το ημερολογίου του μήνα |
| echo hello | Τυπώνει hello |
| echo $HOST | Τυπώνει την τιμή της μεταβλητής HOST |
| finger | Τυπώνει τους τρέχοντες χρήστες |
Παράδειγμα:
University of the Aegean
Dept of Mathematics
Samos - Greece
*** Network Connection on ttyp0
Local Time: 19:00 on Wednesday, 29 October 1997
This is node athena.math.aegean.gr
UNAUTHORIZED ACCESS PROHIBITED
login: dspin
dspin's Password:
Last login: Wed Oct 29 18:29:10 on ttyp0 from kerkis.math.aeg
No mail.
There are no messages in your incoming mailbox.
athena:~> date
Wed Oct 29 19:01:20 EET 1997
athena:~> whoami
dspin
athena:~> echo hello
hello
athena:~> echo $HOST
athena
athena:~> cal
October 1999
S M Tu W Th F S
1 2
3 4 5 6 7 8 9
10 11 12 13 14 15 16
17 18 19 20 21 22 23
24 25 26 27 28 29 30
31
athena:~> finger
Login Name Tty Idle Login Time Office Office Phone
dspin Diomidis Spinelis p0 Oct 29 19:00 [ rls105.math.aeg ]
s95138 Antoniou Niki p1 Oct 29 18:35 [ pyth ]
Το πρόγραμμα βοηθείας
- apropos λέξη
- man εντολή
- 1 Εντολές χρήστη
- 2 Κλήσεις του λειτουργικού συστήματος
- 3 Βιβλιοθήκη της C
- 4 Ειδικά αρχεία
- 5 Μορφές αρχείων
- 6 Παιγνίδια
- 7 Διάφορα
- 8 Εντολές του συστήματος
Παράδειγμα:
athena:~> apropos topological
tsort (1) - Topological sort of a directed graph
athena:~> man tsort
TSORT(1) UNIX Reference Manual TSORT(1)
NAME
tsort - topological sort of a directed graph
SYNOPSIS
tsort [file]
DESCRIPTION
...
Αρχεία
| touch αρχείο | Δημιουργεί ένα κενό αρχείο |
| ls | Τυπώνει τα αρχεία ενός καταλόγου |
| rm | Διαγράφει αρχεία |
| mv | Αλλάζει όνομα σε αρχεία |
| more | Τυπώνει αρχεία σελίδα-σελίδα |
| cat | Ενώνει και τυπώνει αρχεία |
| grep λέξη [αρχείο] | Ψάχνει για τη λέξη στο αρχείο |
Παράδειγμα:
athena:~/eg> touch myfile
athena:~/eg> ls
myfile
athena:~/eg> rm myfile
athena:~/eg> ls
athena:~/eg> touch one
athena:~/eg> ls
one
athena:~/eg> mv one two
athena:~/eg> ls
two
athena:~/eg> grep Elen /etc/passwd
s95128:XyiD4md/Jk9.E:690:100:Xatzinikolaou Eleni:/home/stud/c95/s95128:/bin/tcsh
s96027:savucWqVCSLHQ:587:100:Gkougkoulia Eleni:/home/stud/c96/s96027:/bin/tcsh
s96035:Qys4Lwmsy.uLI:599:100:Drimtzia Eleni:/home/stud/c96/s96035:/bin/tcsh
s96050:FokFq/a5cJBgs:626:100:Kontaraki Eleni:/home/stud/c96/s96050:/bin/tcsh
s96052:7T6k.D7lzkyK.:631:100:Kote Maria-Elena:/home/stud/c96/s96052:/bin/tcsh
s96138:GhPFvxg0F7W.g:840:100:Pozoukidou Eleni:/home/stud/c96/s96138:/bin/tcsh
Αλλαγή εισόδου και εξόδου
Σύντομη λίστα εντολών του διορθωτή vi
Προσοχή όταν δίνετε μία εντολή έχει σημασία αν τα γράμματα
είναι κεφαλαία ή μικρά.
Ανοίγοντας ένα αρχείο:
vi όνομα
Μετακίνηση μέσα στο αρχείο:
|
h (ή το αριστερό βελάκι)
|
Μία θέση αριστερά
|
|
l (ή το δεξί βελάκι)
|
Μία θέση δεξιά
|
|
k (ή το πάνω βελάκι)
|
Μία γραμμή πάνω
|
|
j (ή το κάτω βελάκι)
|
Μία γραμμή κάτω
|
|
w
|
Στην επόμενη λέξη
|
Εισαγωγή και διαγραφή κειμένου:
Ο vi έχει δύο καταστάσεις, κατάσταση εντολών και κατάσταση
εισαγωγής κειμένου.
Για να μπείτε στην κατάσταση εισαγωγής κειμένου δίνετε:
|
i
|
Για να μπείτε στην κατάσταση εισαγωγής κειμένου χωρίς να μετακινηθεί ο δρομέας.
|
|
a
|
Για να μπείτε στην κατάσταση εισαγωγής κειμένου μετακινούμενοι μία θέση δεξιά.
|
|
I
|
Για να μπείτε στην κατάσταση εισαγωγής στην αρχή της γραμμής
|
|
A
|
Για να μπείτε στην κατάσταση εισαγωγής στο τέλος της γραμμής
|
Για να μπείτε στην κατάσταση εντολών δίνετε:
ESC ή ctrl-[
Για να κάνετε αλλαγές στο κείμενό σας:
|
x
|
διαγράφει τον χαρακτήρα όπου είναι ο δρομέας
|
|
dd
|
διαγράφει την γραμμή που είναι ο δρομέας
|
|
u
|
ακυρώνει την τελευταία αλλαγή
|
Αναζήτηση χαρακτήρων/λέξεων μέσα στο κείμενο:
|
/χαρακτήρες
|
Βρίσκει την επόμενη γραμμή όπου εμφανίζεται το "χαρακτήρες".
|
|
?χαρακτήρες
|
Βρίσκει την προηγούμενη γραμμή όπου εμφανίζεται το "χαρακτήρες".
|
|
n
|
Επαναλαμβάνει την αναζήτηση στις επόμενες γραμμές.
|
Σώζοντας και βγαίνοντας από ένα αρχείο:
|
:w
|
Σώζει τις τελευταίες αλλαγές και παραμένει μέσα στο αρχείο.
|
|
:x
|
Σώζει τις τελευταίες αλλαγές και βγαίνει από το αρχείο
|
|
:q!
|
Βγαίνει από το αρχείο χωρίς να σώσει τις αλλαγές
|
Βασισμένο σε κείμενο του Αντώνη Δανάλη
<danalis@edu.physics.uch.gr (http://www.edu.physics.uch.gr/~danalis/index3.html)>
Ο διορθωτής vi: εντολές ανά κατηγορία
Η εντολές που ακολουθούν είναι χωρισμένες σε κατηγορίες ανάλογα με
τη λειτουργία που κάνουν.
Εντολές που σβήνουν ή αντιγράφουν κομμάτια του κειμένου
|
"
|
Ορίζει ένα ενταμιευτή ο οποίος μπορεί να χρησιμοποιηθεί από όλες τις εντολές
που χρησιμοποιούν ενταμιευτές. Αν το " ακολουθείται από ένα γράμμα ή ένα
νούμερο τότε αυτό είναι το όνομα του ενταμιευτή.
|
|
D
|
Σβήνει από εκεί που βρίσκεται ο δρομέας μέχρι το τέλος της γραμμής
|
|
p
|
Αντιγράφει τον ενταμιευτή που του ορίζουμε μετά την θέση ή την γραμμή που
βρίσκεται ο δρομέας. Αν δεν ορίσουμε κάποιον συγκεκριμένο ενταμιευτή τότε
η εντολή p χρησιμοποιεί τον γενικό.(Δείτε το παράδειγμα της εντολής ")
|
|
P
|
Αντιγράφει τον ενταμιευτή που του ορίζουμε πριν την θέση ή την γραμμή που
βρίσκεται ο δρομέας. Αν δεν ορίσουμε κάποιον συγκεκριμένο ενταμιευτή τότε
η εντολή P χρησιμοποιεί τον γενικό.(Δείτε το παράδειγμα της εντολής ")
|
|
x
|
Σβήνει τον χαρακτήρα πάνω στον οποίο βρίσκεται ο δρομέας. Αν πριν το x δώσουμε
ένα αριθμό τότε θα σβηστούν τόσοι χαρακτήρες μετά το δρομέα.
|
|
X
|
Σβήνει τον χαρακτήρα που βρίσκεται πριν το δρομέα.
|
|
d
|
Σβήνει μέχρι εκεί που του ορίζουμε.Αν δώσουμε dd σβήνει όλη την γραμμή. Ό,τι
σβήνεται τοποθετείται στον ενταμιευτή που του ορίζουμε με την εντολή " , αν δεν
ορισθεί ενταμιευτής τότε χρησιμοποιείται ο γενικός.
|
|
Y
|
Καταχωρεί την γραμμή στον ενταμιευτή που ορίζουμε, αν δεν ορίσουμε ενταμιευτή χρησιμοποιεί
τον γενικό.
|
|
y
|
Καταχωρεί στον ενταμιευτή που του ορίζουμε (ή στον γενικό) το κομμάτι του
κειμένου που του ορίζουμε. Οι κανόνες που ακολουθεί είναι αυτοί που
ακολουθεί και η d εκτός από την καταχώρηση μίας γραμμής που γίνεται
δίνοντας
yy
|
Εντολές εισαγωγής κειμένου
|
A
|
Ξεκινάει την εισαγωγή του κειμένου από το τέλος της γραμμής
|
|
I
|
Ξεκινάει την εισαγωγή του κειμένου από την αρχή της γραμμής
|
|
o
|
Ξεκινάει την εισαγωγή του κειμένου στην από κάτω γραμμή από αυτή
που βρίσκεται ο δρομέας.
|
|
O
|
Το κεφαλαίο γράμμα Ο ξεκινάει την εισαγωγή του κειμένου στην από πάνω
γραμμή από αυτή που βρίσκεται ο δρομέας.
|
|
a
|
Ξεκινάει την εισαγωγή κειμένου μία θέση μετά από εκεί που βρίσκεται ο
δρομέας. Συνδυάζοντας την εντολή a με έναν αριθμό n πετυχαίνουμε εισαγωγή
κειμένου n φορές.
|
|
i
|
Ξεκινάει την εισαγωγή κειμένου μία θέση πριν από εκεί που βρίσκεται ο
δρομέας. Συνδυάζοντας την εντολή i με έναν αριθμό n πετυχαίνουμε εισαγωγή
κειμένου n φορές.
|
Μετακίνηση του δρομέα μέσα σε ένα αρχείο
|
^B
|
Πάει πίσω μία σελίδα. Μαζί με ένα νούμερο n γυρνάει n σελίδες πίσω.
|
|
^F
|
Πάει μπροστά μία σελίδα. Μαζί με ένα νούμερο n πάει n σελίδες μπροστά.
|
|
^D
|
Πάει μπροστά μισό παράθυρο. Μαζί με ένα νούμερο n πάει n παράθυρα μπροστά
|
|
^H
|
Μετακινεί το δρομέα μία θέση αριστερά. Μαζί με ένα νούμερο n πάει n θέσεις δεξιά
|
|
^J
|
Μετακινεί το δρομέα μία γραμμή κάτω στην ίδια γραμμή.
Μαζί με ένα νούμερο n πάει n γραμμές κάτω.
|
|
^M
|
Πηγαίνει στον πρώτο χαρακτήρα της επόμενης γραμμής.
|
|
^N
|
Ό,τι και το ^J
|
|
^P
|
Μετακινεί το δρομέα μία γραμμή κάτω στην ίδια γραμμή.
Μαζί με ένα νούμερο n πάει n γραμμές κάτω.
|
|
^U
|
Πάει πίσω μισό παράθυρο. Μαζί με ένα νούμερο n πάει n παράθυρα πίσω
|
|
$
|
Μετακινεί το δρομέα στο τέλος της γραμμής. Μαζί με ένα νούμερο n πάει στο τέλος
της γραμμής που είναι n γραμμές κάτω από το δρομέα.
|
|
%
|
Αν ο δρομέας είναι πάνω σε παρένθεση ή αγκύλη τότε τον μετακινεί σε αυτήν που της ταιριάζει
|
|
(
|
Μετακινεί το δρομέα στην αρχή της περιόδου
|
|
)
|
Μετακινεί το δρομέα στην αρχή της επόμενης περιόδου
|
|
{
|
Μετακινεί το δρομέα στην αρχή της παραγράφου
|
|
}
|
Μετακινεί το δρομέα στην επόμενη παράγραφο
|
|
|
|
n| Μετακινει το δρομέα στην στήλη n
|
|
+
|
Μετακινεί το δρομέα στον πρώτο όχι-κενό χαρακτήρα της επόμενης γραμμής
|
|
-
|
Μετακινεί το δρομέα στον πρώτο όχι-κενό χαρακτήρα της προηγούμενης γραμμής
|
|
^
|
Μετακινεί το δρομέα στον πρώτο όχι-κενό χαρακτήρα της γραμμής
|
|
_
|
Ό,τι και το ^
|
|
0
|
Ο χαρακτήρας μηδέν μετακινεί το δρομέα στην πρώτη στήλη της γραμμής
|
|
B
|
Μετακινεί το δρομέα μία λέξη πίσω
|
|
E
|
Μετακινεί το δρομέα μία λέξη μπροστά
|
|
nG
|
Μετακινεί το δρομέα στην γραμμή n. Αν δε δώσετε n, τότε πάει στο τέλος
του κειμένου.
|
|
H
|
Μετακινεί το δρομέα στον πρώτο όχι-κενό χαρακτήρα στην κορυφή της οθόνης
|
|
L
|
Μετακινεί το δρομέα στον πρώτο όχι-κενό χαρακτήρα στο κάτω μέρος της οθόνης
|
|
M
|
Μετακινεί το δρομέα στον πρώτο όχι-κενό χαρακτήρα στο κέντρο της οθόνης
|
|
W
|
Μετακινεί το δρομέα μία λέξη πίσω
|
|
b
|
Μετακινεί το δρομέα μία λέξη πίσω. Αν ο δρομέας είναι μέσα σε λέξη τότε
τον πάει στο πρώτο της γράμμα
|
|
e
|
Μετακινεί το δρομέα μία λέξη μπροστά. Αν ο δρομέας είναι μέσα σε λέξη τότε
τον πάει στο τελευταίο της γράμμα
|
|
w
|
Ό,τι και το e
|
|
h
|
Μετακινεί το δρομέα μία θέση αριστερά
|
|
j
|
Μετακινεί το δρομέα μία γραμμή κάτω
|
|
k
|
Μετακινεί το δρομέα μία γραμμή πάνω
|
|
l
|
Μετακινεί το δρομέα μία θέση δεξιά
|
Μετακίνηση του δρομέα στην οθόνη
|
n^E
|
Μετακινεί την οθόνη n γραμμές πάνω, χωρίς να την μετακινεί μία γραμμή.
|
|
n^Y
|
Μετακινεί την οθόνη n γραμμές κάτω, χωρίς να την μετακινεί μία γραμμή.
|
|
z
|
Αλλάζει την οθόνη ως εξής: z τοποθετεί την γραμμή στην κορυφή της οθόνης.
z. τοποθετεί την γραμμή στο κέντρο της οθόνης. z- τοποθετεί την γραμμή στο
κάτω μέρος της οθόνης. Αν πριν το z υπάρχει ένα νούμερο n, τότε κάνει αυτές
τις αλλαγές για την γραμμή n. Για παράδειγμα 16z τοποθετεί στην κορυφή της
οθόνης την γραμμή 16
|
Αντικατάσταση κειμένου
|
C
|
Αλλάζει την γραμμή από την θέση του δρομέα μέχρι το τέλος της
|
|
R
|
Αλλάζει τόσους χαρακτήρες όσους δίνουμε και αφήνει άθικτους τους υπόλοιπους
|
|
S
|
Αλλάζει ολόκληρη την γραμμή
|
|
c
|
Αλλάζει την γραμμή μέχρι να βρει μία τελεία. Το cc αλλάζει ολόκληρη την γραμμή
|
|
r
|
Αλλάζει τον χαρακτήρα που βρίσκεται ο δρομέας
|
|
s
|
Αλλάζει τον χαρακτηρα που είναι ο δρομέας και μπαίνει σε insert mode.
Με έναν αριθμό n αλλάζει n χαρακτήρες. Ο τελευταίος χαρακτήρας που είναι
να αλλάξει αντικαθίσταται προσωρινά με ένα $
|
Εντολές για να ψάχνετε μέσα σε ένα κείμενο
|
/
|
Ψάχνει προς τα κάτω το κείμενο για τη συμβολοσειρά (κανονική έκφραση)
που ορίζουμε μετά το /
|
|
?
|
Ψάχνει προς τα επάνω το κείμενο για τη συμβολοσειρά (κανονική έκφραση)
που ορίζουμε μετά το ?
|
|
n
|
Επαναλαμβάνει την τελευταία εντολή / ή ?
|
|
N
|
Ό,τι και το n αλλά στην αντίθετη κατεύθυνση
|
|
f
|
Ψάχνει μέσα στην γραμμή για τον χαρακτήρα που δίνουμε μετά το f και μετακινεί
το δρομέα εκεί.
|
|
F
|
Ψάχνει προς τα πίσω μέσα στην γραμμή για τον χαρακτήρα που δίνουμε μετά το f
και μετακινεί το δρομέα εκεί.
|
|
T
|
Ό,τι και το T αλλά πάει το δρομέα στην επόμενη θέση από τον χαρακτήρα.
|
|
t
|
Ό,τι και το f αλλά πάει το δρομέα στην προηγούμενη θέση από τον χαρακτήρα
|
|
;
|
Επαναλαμβάνει την τελευταία εντολή f ή F ή t ή T
|
|
,
|
Επαναλαμβάνει την τελευταία εντολή f ή F ή t ή T αλλά στην αντίθετη κατεύθυνση
|
Εντολές μορφοποίησης χαρακτήρων και γραμμών
|
~
|
Αλλάζει από κεφαλαίο σε μικρό και από μικρό σε κεφαλαίο το γράμμα που
είναι ο δρομέας
|
|
<<
|
Μετακινεί την γραμμή προς τα αριστερά. Η τιμή του είναι μεταβλητή και
μπορεί να ορισθεί από την set shiftwidth
|
|
>>
|
Μετακινεί την γραμμή προς τα δεξιά. Η τιμή του είναι μεταβλητή και
μπορεί να ορισθεί από την set shiftwidth
|
|
J
|
Ενώνει την γραμμή που βρίσκεται ο δρομέας με την επόμενη. Με ένα νούμερο n
μπροστά ενώνει n γραμμές
|
Εντολές για να σώσετε και να βγείτε από ένα αρχείο
|
^\
|
Μπαίνει σε ΕΧ mode. Ο EX editor είναι αυτός πάνω στον οποίο "χτίστηκε"
ο VI. Για να επιστρέψετε σε vi mode δίνετε :vi
|
|
Q
|
Ό,τι και η ^\
|
|
ZZ
|
Βγαίνει από το αρχείο σώζοντας τις αλλαγές
|
Μερικές ακόμα εντολές
|
^G
|
Δείχνει το όνομα του αρχείου τον συνολικό αριθμό γραμμών που έχει και
τον αριθμό της γραμμής που βρίσκεται ο δρομέας
|
|
^L
|
Καθαρίζει την οθόνη.
|
|
^R
|
Ξανασχεδιάζει την οθόνη και διορθώνει τα λάθη
|
|
^[
|
Το σύμβολο <ctrl>-[ είναι ουσιαστικά το <ESC>
|
|
!
|
Η εντολή ! ξεκινάει ένα shell. Αμα ορίσετε κάποιες συγκεκριμένες γραμμές
τότε χρησιμοποιεί αυτές σαν input και τις αντικαθιστά με το output.
Η !! χρησιμοποιεί σαν input την γραμμή που είναι ο δρομέας.
|
|
&
|
Επαναλαμβάνει την τελευταία εντολή αλλαγής :s
|
|
.
|
Επαναλαμβάνει την τελευταία εντολή
|
|
:
|
Δίνει την δυνατότητα να εκτελεστεί μια εντολή του ex.
|
|
U
|
Φέρνει την γραμμή που είναι ο δρομέας στην γραμμή που ήταν πριν την
αλλάξετε
|
|
m
|
"Σημαδεύει" την θέση με τον χαρακτήρα που ακολουθεί το m
|
|
u
|
Ακυρώνει την τελευταία αλλαγή. Δύο συνεχόμενα u αφήνουν το αρχείο όπως ήταν
πριν από αυτά
|
Εντολές του EX
Ο vi editor είναι βασισμένος πάνω σε έναν διορθωτή γραμμών, τον ex. Ετσι ο
vi δίνει την δυνατότητα να εκτελεστούν οι εντολές του ex.
|
:ab string strings
|
Κάνει συντομογραφία μιας συμβολοσειράς σε μια άλλη. Ετσι αν δώσετε:
:ab usa United States of America
τότε κάθε φορά που θα γράφετε usa θα εμφανίζεται το
United States of America
|
|
:map keys new_seq
|
Με την μέθοδο του mapping μπορείτε να κάνετε συντομογραφίες σε εντολες.
|
|
:q
|
Βγαίνει από το αρχείο. Αν έχετε κάνει αλλαγές που δεν έχετε σώσει τότε
εμφανίζεται ένα μήνυμα και δεν βγαίνει από το αρχείο
|
|
:q!
|
Βγαίνει από το αρχείο χωρίς να σώσει τις τελευταίες αλλαγές
|
|
:s/from/to/options
|
Αντικαθιστά την λέξη from στην λέξη to.
|
|
:set [all]
|
Ορίζει της μεταβλητές του vi. Η εντολή set all δείχνει όλες τις μεταβλητές
και για όσες υπάρχει, την τιμή τους.
|
|
:una string
|
κάνει το ανάποδο από την ab, δηλαδή αφαιρεί από μια συμβολοσειρά την ιδιότητά
του να είναι συντομογραφία κάποιας άλλης.
|
|
:unm keys
|
Το αντίστοιχο του una αλλά για την εντολή map
|
|
:vi filename
|
Ξεκινάει την επεξεργασία ενός άλλου αρχείου.
|
|
:w
|
Σώζει το αρχείο και παραμένει μέσα σε αυτό
|
|
:w new_file
|
Σώζει τα περιεχόμενα του αρχείου σε ένα άλλο με όνομα new_file
|
|
:w >> filename
|
Προσθέτει το αρχείο, κάτω από το αρχείο filename
|
|
:wq
|
Σώζει τις τελευταίές αλλαγές και βγαίνει από το αρχείο
|
|
:x
|
Ότι και το x
|
Βασισμένο σε κείμενο του Αντώνη Δανάλη
<danalis@edu.physics.uch.gr (http://www.edu.physics.uch.gr/~danalis/index3.html)>
Εργαλεία γλωσσικών επεξεργαστών
Το λειτουργικό σύστημα Unix παραδοσιακά περιλαμβάνει πολλά εργαλεία
τεχνολογίας γλωσσικών επεξεργαστών.
Στο μάθημα αυτό θα χρησιμοποιήσουμε τα παρακάτω εργαλεία:
Χρήση του συμβολομεταφραστή gas
Η χρήση του συμβολομεταφραστή γίνεται μέσω του μεταγλωττιστή της C.
Αυτός καλείται με την εντολή gcc:
gcc -o output filename.s
όπου output είναι το εκτελέσιμο αρχείο που θα δημιουργηθεί και
filename.s είναι το αρχείο που θα περιέχει τον πηγαίο κώδικα στη συμβολική
γλώσσα.
Για να εκτελέσουμε το αρχείο, αν ο τρέχων κατάλογος (.) δεν είναι στο μονοπάτι
των καταλόγων από τους οποίους εκτελούνται τα προγράμματα πρέπει να προσδιορίσουμε
τον τρέχοντα κατάλογο ως τμήμα της εντολής που θέλουμε να εκτελέσουμε:
./mycommand
Έτσι ο κύκλος για την υλοποίηση ενός προγράμματος σε συμβολκή γλώσσα είναι ο
παρακάτω:
vi hello.s
gcc -o hello hello.s
./hello
Αν έχουμε κάνει κάποιο λογικό λάθος στο πρόγραμμα θα εμφανιστεί στην οθόνη μας
το παρακάτω μήνυμα:
Segmentation fault (core dumped)
Γενική βιβλιογραφία
- Alfred V. Aho, Brian W.
Kernighan, and Peter J. Weinberger.
The AWK Programming Language.
Addison-Wesley, 1988.
- S. R. Bourne.
An introduction to the UNIX shell.
In UNIX Users' Supplementary Documents. Computer Systems
Research Group, Department of Electrical Engineering and Computer Science,
University of California, Berkeley, California 94720, April 1986.
4.3 Berkeley Software Distribution.
- Dan Franklin.
UNIX: Rights and wrongs.
In Mitchell Waite, editor, UNIX Papers for UNIX Developers and Power
Users, chapter 1, pages 2-40. Howard W. Sams & Company, 1987.
- David Huelsbeck.
Awk power plays.
In Mitchell Waite, editor, UNIX Papers for UNIX Developers and Power
Users, chapter 5, pages 152-184. Howard W. Sams & Company, 1987.
- Brian W. Kernighan and Rob
Pike.
The UNIX Programming Environment.
Prentice-Hall, 1984.
- Brian W. Kernighan and
P. J. Plauger.
Software Tools.
Addison-Wesley, 1976.
- Brian W. Kernighan and
Dennis M. Ritchie.
The C Programming Language.
Prentice-Hall, second edition, 1988.
- Don Libes and Sandy
Ressler.
Life with UNIX.
Prentice-Hall, 1989.
- Dennis M. Ritchie and
Ken Thompson.
The UNIX time-sharing system.
Communications of the ACM, 17(7):365-375, July 1974.
- Dennis M. Ritchie.
The evolution of the UNIX time-sharing system.
Bell System Technical Journal, 63(8):1577-1593, October 1984.
- Dennis M. Ritchie.
A retrospective.
Bell System Technical Journal, 56(6):1947-1969, July-August
1987.
- John Sebes.
Comparing UNIX shells.
In Mitchell Waite, editor, UNIX Papers for UNIX Developers and Power
Users, chapter 4, pages 122-151. Howard W. Sams & Company, 1987.
- AT & T, editor.
UNIX System Readings and Applications, volume II.
Prentice-Hall, 1987.
- Larry Wall and Randal L.
Schwartz.
Programming Perl.
O'Reilly and Associates, Sebastopol, CA, USA, 1990.
Ασκήσεις
Συμβολική γλώσσα
- Γράψτε ένα πρόγραμμα σε συμβολική γλώσσα Intel 386 σε περιβάλλον
Unix το οποίο να τυπώνει τους αριθμούς από το 0 μέχρι το 9.
Πεπερασμένα αυτόματα και κανονικές εκφράσεις
Εισαγωγή
- Ο σχεδιασμός και η υλοποίηση γλωσσικών εργαλείων υποστηρίζεται
από ένα ευρύ φάσμα θεωρητικής γνώσης.
- Αυτή περιλαμβάνει μεταξύ άλλων:
- τον αφηρημένο ορισμό μιας γλώσσας,
- τον ορισμό ενός αυτομάτου που μπορεί να αναγνωρίσει μια γλώσσα,
- τον ορισμό γραμματικών που περιγράφουν μια γλώσσα,
- την ισοδυναμία αυτομάτων και γλωσσών και
- αλγορίθμους για την αποδοτική υλοποίηση των παραπάνω.
Συμβολισμοί
- Αλφάβητο (alphabet):
-
Πεπερασμένο σύνολο συμβόλων
- Συμβολοσειρά (string):
-
Πεπερασμένη ακολουθία συμβόλων. Το μήκος της συμβολοσειράς
χ συμβολίζεται ως |χ|.
- Κενή συμβολοσειρά (empty string):
-
Συμβολοσειρά με μήκος 0. Συμβολίζεται ως ε.
- Παράθεση (concatenation):
-
Η δημιουργία μιας νέας συμβολοσειράς από δύο άλλες (x, y) με τη σειριακή παράθεση
των συμβόλων τους. Συμβολίζεται ως xy
- Γλώσσα (language):
-
Ένα υποσύνολο των συμβολοσειρών που μπορούν να δημιουργηθούν από ένα συγκεκριμένο
αλφάβητο.
Με βάση τον ορισμό της γλώσσας ορίζουμε:
Πεπερασμένα αυτόματα
Το θεωρητικό μοντέλο για την αναγνώριση μιας γλώσσας είναι ένα
αυτόματο (automaton).
Δύο αυτόματα τα οποία θα εξετάσουμε είναι τα:
Τα πεπερασμένα αυτόματα ορίζονται από την πεντάδα
Μ = (Κ, Σ, δ, S, F):
- K
- Πεπερασμένο σύνολο καταστάσεων
- Σ
- Πεπερασμένο αλφάβητο εισόδου
- δ
- συνάρτηση αλλαγής κατάστασης (transition function)
από μια κατάσταση Χ σε μια Χ' με βάση ένα σύμβολο εισόδου σ.
δ(Χ, σ) = Χ'
- S
- Αρχική κατάσταση
- F
- Σύνολο τελικών καταστάσεων
Αν η συνάρτηση δ είναι μονότιμη τότε το αυτόματο αυτόματο καλείται
ντετερμινιστικό πεπερασμένο αυτόματο (ΝΠΑ) (deterministic finite automaton (DFA)).
Αντίθετα, αν για κάποιες τιμές (Χ, σ) της δ υπάρχουν πολλές πιθανές νέες
καταστάσεις X' τότε το αυτόματο καλείται
μη ντετερμινιστικό πεπερασμένο αυτόματο (ΜΠΑ) (non-deterministic finite automaton (NFA)).
Οι γλώσσες που αναγνωρίζονται από τα πεπερασμένα αυτόματα λέγονται
κανονικές γλώσσες (regular languages).
Οι γλώσσες αυτές είναι κατάλληλες για να περιγράψουν τις λεκτικές μονάδες
ενός προγράμματος.
Ένα πεπερασμένο αυτόματο μπορεί να παρασταθεί ως:
Κανονικές εκφράσεις
Μια κανονική έκφραση (regular expression)
είναι ένας συμβολισμός κατάλληλος για την περιγραφή μιας
κανονικής γλώσσας.
Πολλά εργαλεία προγραμματισμού βασίζονται σε κανονικές εκφράσεις
για την περιγραφή και την αναγνώριση συμβολοσειρών.
Μπορούμε να ορίσουμε μια κανονική έκφραση σύμφωνα με τους παρακάτω
κανόνες:
- Για ένα σύμβολο της αλφαβήτου a η κανονική έκφραση a συμβολίζει τη γλώσσα
{a}.
- Αν R και S δύο κανονικές εκφράσεις για τις γλώσσες
LR και LS τότε:
- η έκφραση R|S συμβολίζει τη γλώσσα LR U LS.
- η έκφραση R.S συμβολίζει τη γλώσσα LR . LS.
- η έκφραση R* συμβολίζει τη γλώσσα LR*.
- η έκφραση R+ συμβολίζει τη γλώσσα LR+.
Ο τελεστής * έχει την υψηλότερη και ο τελεστής | τη χαμηλότερη προτεραιότητα.
Κανονικές εκφράσεις στο Unix
Σε πολλά εργαλεία του Unix
οι κανονικές εκφράσεις επιτρέπουν τον ορισμό σύνθετων συμβολοσειρών με
δηλωτικό τρόπο.
Η εντολή egrep επιτρέπει την αναζήτηση γραμμών που ικανοποιούν μια κανονική
έκφραση μέσα σε ένα αρχείο.
Τα παρακάτω σύμβολα έχουν ειδικό νόημα:
- ^
- Αρχή της γραμμής
- $
- Τέλος της γραμμής
- .
- Οποιοδήποτε γράμμα
- [abc]
- Ένα από τα γράμματα a, b, ή c
- [a-z]
- Ένα από τα γράμματα a μέχρι z
- [^abc]
- Οποιοδήποτε γράμμα εκτός από τα a, b, και c.
- Έκφραση*
- Η έκφραση μηδέν ή περισσότερες φορές
- Έκφραση+
- Η έκφραση μία ή περισσότερες φορές
- Έκφραση?
- Η έκφραση μία ή καμία φορά
- Έκφραση1|Έκφραση1
- Η έκφραση1 ή η έκφραση2
- (Έκφραση)
- Το περιεχόμενο στην παρένθεση
Παράδειγμα:
(με την εντολή cd ~dspin φτάνετε σε έναν κατάλογο που περιέχει ένα αρχείο με πολλές λέξεις (words))
athena:~> egrep 'abo' words
...
sabotage
seaboard
taboo
thereabouts
turnabout
vagabond
whereabout
...
athena:~> egrep '^abo' words
aboard
abode
abolish
abolition
abominable
abominate
aboriginal
athena:~> egrep bent words
absorbent
bent
benthic
debenture
incumbent
recumbent
athena:~> egrep 'bent$' words
absorbent
bent
incumbent
recumbent
athena:~> egrep "heaven|hell" words
eggshell
heaven
heavenly
heavens
hell
hellfire
hellish
hello
hells
...
athena:~> egrep "(ga)(ba)+" words
gabardine
megabaud
athena:~> egrep pe+l words
..
peel
peeled
...
Ασκήσεις
- Να γράψετε ως κανονικές εκφράσεις τις παρακάτω εκφράσεις του egrep:
w[xyz]k*
a[^a-x]q
a(b?)
- Να σχεδιάσετε ένα γράφο μετάβασης που να αναγνωρίζει τη γλώσσα με τις
παρακάτω συμβολοσειρές:
Kadafi
Gadafi
Ghadafi
Khadafi
- Να σχεδιάσετε ένα γράφο μετάβασης που να αναγνωρίζει την κανονική
έκφραση a* . (b | c) . (d | b)+.
Βιβλιογραφία
- Alfred V. Aho, John E.
Hopcroft, and Jeffrey D. Ullman.
The
Design and Analysis of Computer Algorithms, pages 318–3335.
Addison-Wesley, 1974.
- Alfred V. Aho, Ravi Sethi,
and Jeffrey D. Ullman.
Compilers, Principles, Techniques, and Tools, pages 83–157.
Addison-Wesley, 1985.
Λεκτική ανάλυση
Ο λεκτικός αναλυτής
Ο λεκτικός αναλυτής παρέχει τις παρακάτω λειτουργίες:
- Διαχωρίζει το εισερχόμενο κείμενο σε
λεκτικές μονάδες (tokens) και το μεταφέρει
με τον τρόπο αυτό στο συντακτικό αναλυτή.
- Αποθηκεύει τα σύμβολα που διαβάζει σε πίνακα συμβόλων.
- Αποθηκεύει άλλα στοιχεία όπως τις συμβολοσειρές σε δυναμική μνήμη.
- Αναγνωρίζει λεκτικά λάθη στην είσοδο (π.χ. σύμβολα που δεν
επιτρέπονται στη γλώσσα).
- Αφαιρεί τα σχόλια
- Συσχετίζει αριθμούς γραμμών με στοιχεία της εισόδου του.
Με τον τρόπο αυτό διαχωρίζονται οι εργασίες της λεκτικής και της
συντακτικής ανάλυσης και κάθε μια υλοποιείται με τον πιο αποδοτικό τρόπο.
Λεκτικές μονάδες
- Τα στοιχεία μιας γλώσσας χωρίζονται σε λεκτικές μονάδες.
- Ο χωρισμός σε λεκτικές μονάδες συχνά δεν είναι προκαθορισμένος.
- Τυπικές λεκτικές μονάδες που ορίζονται είναι:
- Κάθε λεκτική μονάδα συσχετίζεται από το λεκτικό αναλυτή με τον τύπο
της (π.χ. ακέραια σταθερά) και την τιμή της (π.χ. 42).
- Μη προκαθορισμένες λεκτικές μονάδες που δεν υποστηρίζονται άμεσα
από τη γλώσσα υλοποίησης πρέπει να αποθηκευτούν σε πίνακα συμβόλων (για τα
ονόματα) ή σε δυναμική μνήμη.
- Οι δεσμευμένες λέξεις τυπικά διαχωρίζονται μεταξύ τους κατά το στάδιο της
λεκτικής ανάλυσης.
- Συχνά η αναγνώριση των δεσμευμένων λέξεων γίνεται με τη χρήση
συναρτήσεων κατακερματισμού.
Διεπαφή
Οπισθοδρόμηση
Υλοποίηση με διάγραμμα μετάβασης
Ασκήσεις
- Να υλοποιήσετε σε C έναν λεκτικό αναλυτή που να αναγνωρίζει τα
παρακάτω λεκτικά σύμβολα:
- ακέραιοι
- μεταβλητές (όπως της C)
- τελεστής +
- τελεστής -
- τελεστής *
- τελεστής /
Η συνάρτηση του λεκτικού αναλυτή θα λέγεται yylex και θα επιστρέφει:
των κωδικό του χαρακτήρα για τους τελεστές, 256 για τους ακέραιους,
257 για τις μεταβλητές και -1 στο τέλος του αρχείου.
Ακόμα θα φυλάει στα πεδία της ένωσης yylval s και i τις τιμές των
μεταβλητών και των ακεραίων αντίστοιχα.
Σε περίπτωση λάθους ο λεκτικός αναλυτής θα τερματίζει τη λειτουργία του
εμφανίζοντας ένα μήνυμα λάθους.
Ο λεκτικός αναλυτής θα καλείται από το παρακάτω πρόγραμμα:
#include <stdio.h>
union {
char *s; /* Variable name */
int i; /* Integer value */
} yylval;
int yylex();
main()
{
int k;
while ((k = yylex()) != -1) {
switch (k) {
case 256:
printf("INT: %d\n", yylval.i);
break;
case 257:
printf("VAR: %s\n", yylval.s);
break;
default:
printf("OPERATOR: %c\n", k);
break;
}
}
}
Βιβλιογραφία
- Alfred V. Aho, Ravi Sethi,
and Jeffrey D. Ullman.
Compilers, Principles, Techniques, and Tools, pages 83–157.
Addison-Wesley, 1985.
- John M. Dedourek,
Uday G. Gujar, and Marion E. McIntyre.
Scanner design.
Software: Practice & Experience, 10:959–972, 1980.
- V. P. Heuring.
The automatic generation of fast lexical analysers.
Software: Practice & Experience, 16(9):801–808, September
1986.
- R. Nigel Horspool
and Michael R. Levy.
Mkscan — an interactive scanner generator.
Software: Practice & Experience, 17(6):369–378, June 1987.
- Douglas C. Schmidt.
Gperf: A perfect hash function generator.
In USENIX C++ Conference, pages 87–100, San Francisco, CA,
USA, April 1990. Usenix Association.
- W. M. Waite.
Treatment of tab characters by a compiler.
Software: Practice & Experience, 15(11):1121–1123, November
1985.
- W. M. Waite.
The cost of lexical analysis.
Software: Practice & Experience, 16(5):473–488, May 1986.
Το μεταεργαλείο lex
Μεταεργαλεία
- Τα μεταεργαλεία είναι εργαλεία για τη δημιουργία άλλων εργαλείων.
- Παραδείγματα τέτοιων εργαλείων είναι:
- Τα μεταεργαλεία αυτά δέχονται τυπικά μια δηλωτική περιγραφή του εργαλείου
που θέλουμε να υλοποιήσουμε και δημιουργούν τον αντίστοιχο κώδικα.
- Προϋπόθεση για την ύπαρξη ενός τέτοιου εργαλείου είναι η ύπαρξη θεωρίας
και αλγορίθμων που να οδηγεί από τη δηλωτική περιγραφή στον τελικό κώδικα.
Το μεταεργαλείο lex
- Το μεταεργαλείο lex επιτρέπει την αυτόματη δημιουργία
σαρωτών κειμένου (text scanners) και κατ' επέκταση
λεκτικών αναλυτών.
- Ως είσοδο δέχεται κανονικές εκφράσεις και ενέργειες .
- Ως έξοδο παράγει κώδικα σαρώνει το κείμενο εισόδου και εκτελεί τις
αντίστοιχες ενέργειες ανάλογα με τις κανονικές εκφράσεις που αντιστοιχούν
στο κείμενο.
- Η λειτουργία του κώδικα που παράγει βασίζεται σε αιτιοκρατικά πεπερασμένα
αυτόματα.
Διαδικασία χρήσης
- Το αρχείο εισόδου για το εργαλείο lex έχει κατάληξη .l
- Το αρχείο εισόδου περιέχει δηλωτική περιγραφή της λειτουργίας
του τελικού σαρωτή (κανονικές εκφράσεις και ενέργειες).
- Το εργαλείο lex διαβάζει το αρχείο αυτό και δημιουργεί ένα αρχείο
σε C με όνομα lex.yy.c που υλοποιεί το σαρωτή που προδιαγράψαμε.
- Ο σαρωτής είναι υλοποιημένος στη συνάρτηση yylex().
- Η είσοδος του σαρωτή που δημιουργείται είναι το πρότυπο αρχείο εισόδου
(standard input).
- Για τη λειτουργία του σαρωτή τυπικά καλούμε τη συνάρτηση yylex() μέσω
της συνάρτησης main() την οποία υλοποιούμε εμείς.
Αρχείο εισόδου
- Το αρχείο εισόδου αποτελείται από τα παρακάτω τμήματα:
- Η δομή του αρχείου είναι η παρακάτω:
definitions
%%
rules
%%
user code
- Οι ορισμοί επιτρέπουν τον ορισμό κανονικών εκφράσεων με τη σύνταξη:
name definition.
- Παράδειγμα:
DIGIT [0-9]
ID [a-z][a-z0-9]*
- Στους ορισμούς προσθέτουμε και την εντολή:
%option noyywrap
για να δηλώσουμε πως η είσοδός μας αποτελείται από ένα μόνο αρχείο.
- Στους ορισμούς μπορούμε να ορίσουμε και μεταβλητές της C για
δική μας χρήση αρχίζοντας της γραμμή με κενό:
DIGIT [0-9]
int numlines;
- Τέλος στους ορισμούς μπορούμε να ορίσουμε πρόσθετα αρχεία εισόδου
μέσα σε ενότητες %{ και %}:
%{
#include <math.h>
%}
- Οι κανόνες ορίζουν ενέργειες που αντιστοιχούν σε κανονικές εκφράσεις (ΚΕ)
της εισόδου με τη σύνταξη:
pattern action.
όπου pattern είναι μια ΚΕ και action κώδικας σε C.
- Παράδειγμα:
("hi")* printf("hi or hihi or hihihi ...\n");
DIGIT printf("Read one digit\n");
- Τέλος ο κώδικας χρήστη αντιγράφεται ως έχει στον παραγόμενο κώδικα.
Κανονικές εκφράσεις
Στο αρχείο εισόδου επιτρέπεται η παρακάτω σύνταξη για τις κανονικές
εκφράσεις:
- `x'
-
match the character `x'
- `.'
-
any character (byte) except newline
- `[xyz]'
-
a "character class"; in this case, the pattern
matches either an `x', a `y', or a `z'
- `[abj-oZ]'
-
a "character class" with a range in it; matches
an `a', a `b', any letter from `j' through `o',
or a `Z'
- `[^A-Z]'
-
a "negated character class", i.e., any character
but those in the class. In this case, any
character EXCEPT an uppercase letter.
- `[^A-Z\n]'
-
any character EXCEPT an uppercase letter or
a newline
- `r*'
-
zero or more r's, where r is any regular expression
- `r+'
-
one or more r's
- `r?'
-
zero or one r's (that is, "an optional r")
- `r{2,5}'
-
anywhere from two to five r's
- `r{2,}'
-
two or more r's
- `r{4}'
-
exactly 4 r's
- `{name}'
-
the expansion of the "name" definition
(see above)
- `"[xyz]\"foo"'
-
the literal string: `[xyz]"foo'
- `\x'
-
if x is an `a', `b', `f', `n', `r', `t', or `v',
then the ANSI-C interpretation of \x.
Otherwise, a literal `x' (used to escape
operators such as `*')
- `\0'
-
a NUL character (ASCII code 0)
- `\123'
-
the character with octal value 123
- `\x2a'
-
the character with hexadecimal value
2a
- `(r)'
-
match an r; parentheses are used to override
precedence (see below)
- `rs'
-
the regular expression r followed by the
regular expression s; called "concatenation"
- `r|s'
-
either an r or an s
- `r/s'
-
an r but only if it is followed by an s. The text
matched by s is included when determining whether this rule is
the longest match, but is then returned to the input before
the action is executed. So the action only sees the text matched
by r. This type of pattern is called trailing context.
(There are some combinations of `r/s' that
flex
cannot match correctly; see notes in the Deficiencies / Bugs section
below regarding "dangerous trailing context".)
- `^r'
-
an r, but only at the beginning of a line (i.e.,
which just starting to scan, or right after a
newline has been scanned).
- `r$'
-
an r, but only at the end of a line (i.e., just
before a newline). Equivalent to "r/\n".
Note that flex's notion of "newline" is exactly
whatever the C compiler used to compile flex
interprets '\n' as; in particular, on some DOS
systems you must either filter out \r's in the
input yourself, or explicitly use r/\r\n for "r$".
- `<s>r'
-
an r, but only in start condition s (see
below for discussion of start conditions)
<s1,s2,s3>r
same, but in any of start conditions s1,
s2, or s3
- `<*>r'
-
an r in any start condition, even an exclusive one.
- `<<EOF>>'
-
an end-of-file
<s1,s2><<EOF>>
an end-of-file when in start condition s1 or s2
Τιμές προσβάσιμες στο χρήστη
Απλό παράδειγμα
int num_lines = 0, num_chars = 0;
%%
\n ++num_lines; ++num_chars;
. ++num_chars;
%%
main()
{
yylex();
printf( "# of lines = %d, # of chars = %d\n",
num_lines, num_chars );
}
Παράδειγμα χρήσης
athena:~/t> cat foo.l
%option noyywrap
int num_lines = 0, num_chars = 0;
%%
\n ++num_lines; ++num_chars;
. ++num_chars;
%%
main()
{
yylex();
printf( "# of lines = %d, # of chars = %d\n",
num_lines, num_chars );
}
athena:~/t> lex foo.l
athena:~/t> cc -o foo lex.yy.c
athena:~/t> foo <foo.l
# of lines = 15, # of chars = 261
athena:~/t>
Σύνθετο παράδειγμα
/* scanner for a toy Pascal-like language */
%{
/* need this for the call to atof() below */
#include <math.h>
%}
DIGIT [0-9]
ID [a-z][a-z0-9]*
%%
{DIGIT}+ {
printf( "An integer: %s (%d)\n", yytext,
atoi( yytext ) );
}
{DIGIT}+"."{DIGIT}* {
printf( "A float: %s (%g)\n", yytext,
atof( yytext ) );
}
if|then|begin|end|procedure|function {
printf( "A keyword: %s\n", yytext );
}
{ID} printf( "An identifier: %s\n", yytext );
"+"|"-"|"*"|"/" printf( "An operator: %s\n", yytext );
"{"[^}\n]*"}" /* eat up one-line comments */
[ \t\n]+ /* eat up whitespace */
. printf( "Unrecognized character: %s\n", yytext );
%%
main()
{
yylex();
}
Τρόπος λειτουργίας
- Η λειτουργία του lex βασίζεται στην δημιουργία ενός ΜΠΑ από το αρχείο
εισόδου.
- Στη συνέχεια το ΜΠΑ μετατρέπεται σε ΝΠΑ.
- Στο αρχείο εξόδου περιέχεται κώδικας C ο οποίος υλοποιεί τη λειτουργία
του ΝΠΑ καθώς και οι αντίστοιχοι πίνακες μετάβασης.
- Για λόγους απόδοσης οι χαρακτήρες εισόδου κατανέμονται σε κλάσεις
ισοδυναμίας και αυτές σε μετακλάσεις ισοδυναμίας.
Με τον τρόπο αυτό περιορίζεται ο αριθμός των καταστάσεων.
Παράδειγμα
Αρχείο εισόδου
%option noyywrap
%%
hi printf("HI\n");
\. printf("DOT\n");
%%
main()
{
yylex();
}
Μη αιτιοκρατικό πεπερασμένο αυτόματο
Το αυτόματο αρχίζει από την κατάσταση 12.
Από κάθε κατάσταση μπορεί να οδηγηθεί σε δύο νέες καταστάσεις Κ1, Κ2.
(ε είναι το κενό σύμβολο).
συμβ. Κ1 Κ2
Κατάσταση 1 ε : 0, 0
Κατάσταση 2 ε : 0, 0
Κατάσταση 3 h : 4, 0 // Διάβασε h
Κατάσταση 4 i : 5, 0 // Διάβασε i
Κατάσταση 5 ε : 0, 0 [1] // Αναγνώρισε hi
Κατάσταση 6 ε : 1, 3
Κατάσταση 7 . : 8, 0 // Διάβασε .
Κατάσταση 8 ε : 0, 0 [2] // Αναγνώρισε .
Κατάσταση 9 ε : 6, 7
Κατάσταση 10 EOF: 11, 0
Κατάσταση 11 ε : 0, 0 [3] // Τέλος του αρχείου
Κατάσταση 12 ε : 9, 10
Κλάσεις ισοδυναμίας
\000 = -1 ' ' = 1 @ = 1 ` = 1
\001 = 1 ! = 1 A = 1 a = 1
\002 = 1 " = 1 B = 1 b = 1
\003 = 1 # = 1 C = 1 c = 1
\004 = 1 $ = 1 D = 1 d = 1
\005 = 1 % = 1 E = 1 e = 1
\006 = 1 & = 1 F = 1 f = 1
\a = 1 ' = 1 G = 1 g = 1
\b = 1 ( = 1 H = 1 h = 3
\t = 1 ) = 1 I = 1 i = 4
\n = 1 * = 1 J = 1 j = 1
\v = 1 + = 1 K = 1 k = 1
\f = 1 , = 1 L = 1 l = 1
\r = 1 - = 1 M = 1 m = 1
\016 = 1 . = 2 N = 1 n = 1
\017 = 1 / = 1 O = 1 o = 1
\020 = 1 0 = 1 P = 1 p = 1
\021 = 1 1 = 1 Q = 1 q = 1
\022 = 1 2 = 1 R = 1 r = 1
\023 = 1 3 = 1 S = 1 s = 1
\024 = 1 4 = 1 T = 1 t = 1
\025 = 1 5 = 1 U = 1 u = 1
\026 = 1 6 = 1 V = 1 v = 1
\027 = 1 7 = 1 W = 1 w = 1
\030 = 1 8 = 1 X = 1 x = 1
\031 = 1 9 = 1 Y = 1 y = 1
\032 = 1 : = 1 Z = 1 z = 1
\033 = 1 ; = 1 [ = 1 { = 1
\034 = 1 < = 1 \ = 1 | = 1
\035 = 1 = = 1 ] = 1 } = 1
\036 = 1 > = 1 ^ = 1 ~ = 1
\037 = 1 ? = 1 _ = 1 \177 = 1
Μετακλάσεις ισοδυναμίας
1 = 1
2 = 1
3 = 1
4 = 2
Αιτιοκρατικό πεπερασμένο αυτόματο
Κατάσταση # 1:
1 4
2 5 // .
3 6 // h
4 4
Κατάσταση # 2:
1 4
2 5 // .
3 6 // h
4 4
Κατάσταση # 3:
Κατάσταση # 4:
Κατάσταση # 5: // Αναγνώρισε .
Κατάσταση # 6:
4 7 // i
Κατάσταση # 7: // Αναγνώρισε hi
Παραγόμενος κώδικας σε C (τμήματα)
/* A lexical scanner generated by flex */
/* ... */
/* Πίνακες μετάβασης */
static yyconst short int yy_def[10] =
{ 0,
8, 1, 8, 8, 8, 9, 8, 0, 8
} ;
static yyconst short int yy_nxt[12] =
{ 0,
4, 5, 6, 4, 7, 8, 3, 8, 8, 8,
8
} ;
static yyconst short int yy_chk[12] =
{ 0,
1, 1, 1, 1, 9, 3, 8, 8, 8, 8,
8
} ;
/* ... */
/* Υλοποίηση του ΝΠΑ */
yy_match:
do
{
register YY_CHAR yy_c = yy_ec[YY_SC_TO_UI(*yy_cp)];
while ( yy_chk[yy_base[yy_current_state] + yy_c] != yy_current_state )
{
yy_current_state = (int) yy_def[yy_current_state];
if ( yy_current_state >= 9 )
yy_c = yy_meta[(unsigned int) yy_c];
}
yy_current_state = yy_nxt[yy_base[yy_current_state] + (unsigned int) yy_c];
*yy_state_ptr++ = yy_current_state;
++yy_cp;
}
/* ... */
/* Υλοποίηση ενεργειών χρήστη */
switch ( yy_act )
{ /* beginning of action switch */
case 1:
printf("HI\n");
break;
case 2:
printf("DOT\n");
break;
/* ... */
/* Κώδικας χρήστη */
main()
{
yylex();
}
Ασκήσεις
- Να υλοποιήσετε με το μεταεργαλείο lex έναν λεκτικό αναλυτή που να
αναγνωρίζει τα παρακάτω λεκτικά σύμβολα:
- ακέραιοι
- μεταβλητές (όπως της C)
- δεσμευμένη λέξη if
- δεσμευμένη λέξη else
- δεσμευμένη λέξη while
- δεσμευμένη λέξη for
- δεσμευμένη λέξη switch
- δεσμευμένη λέξη case
Ο λεκτικός αναλυτής θα τυπώνει στην έξοδό του τον τύπο του κάθε συμβόλου που
θα αναγνωρίζει καθώς και την τιμή του.
Παράδειγμα:
Read integer (42)
Read variable (i)
Read keyword (while)
Βιβλιογραφία
- Free
Software Foundation.
Flex - a scanner
generator.
Available online: http://www.gnu.org/manual/flex-2.5.4/flex.html, November
1998.
- Michael E. Lesk.
Lex — a lexical analyzer generator.
Computer Science Technical Report 39, Bell Laboratories, Murray Hill, NJ, USA,
October 1975.
- John Levine, Tony Mason,
and Doug Brown.
Lex and Yacc.
O'Reilly & Associates, second edition, 1992.
Αυτόματα στοίβας και γραμματικές
Αυτόματα στοίβας
Τα πεπερασμένα αυτόματα δεν μπορούν να αναγνωρίσουν έναν μεγάλο αριθμό
από γλώσσες που έχουν πρακτική σημασία στην πληροφορική (π.χ.
όλες τις γλώσσες υψηλού επιπέδου).
Για το λόγο αυτό ορίζουμε και εξετάζουμε τα ισχυρότερα αυτόματα στοίβας.
Τα αυτόματα στοίβας (ΑΣ) ορίζονται από την εξάδα
Μ = (Κ, Σ, Γ, δ, q0, Z0)
- K
- Πεπερασμένο σύνολο καταστάσεων
- Σ
- Αλφάβητο εισόδου
- Γ
- Αλφάβητο για τη στοίβα
- δ
- Σύνολο κινήσεων που εκτελεί το αυτόματο
- q0
- Αρχική κατάσταση
- Ζ0
- Αρχική σύμβολο της στοίβας
Κάθε εντολή του ΑΣ ονομάζεται κίνηση (move).
Η κίνηση ορίζεται από:
- την κατάσταση του ΑΣ,
- το σύμβολο στην κορυφή της στοίβας,
- το σύμβολο εισόδου.
Όταν σε κάθε τριάδα αντιστοιχεί μια το πολύ κίνηση τότε το αυτόματο λέγεται
ντετερμινιστικό αυτόματο στοίβας (ΝΑΣ) (deterministic stack automaton (DSA)).
Αντίθετα, αν για κάποιες τιμές της δ υπάρχουν πολλές πιθανές κινήσεις
τότε το αυτόματο καλείται
μη ντετερμινιστικό αυτόματο στοίβας (ΜΑΣ) (non-deterministic stack automaton (NSA)).
(Οι λέξη ντετερμινιστικό που εμφανίζεται στην ελληνική βιβλιογραφία είναι
συνώνυμη με τη λέξη αιτιοκρατικό).
Η λειτουργία του ΑΣ ορίζεται από τρεις υποεντολές που εκτελούνται διαδοχικά:
- την υποεντολή της στοίβας
- την υποεντολή εισόδου
- την υποεντολή επόμενης κατάστασης
Οι εντολές μπορούν να εκτελέσουν τις παρακάτω λειτουργίες:
- υποεντολή της στοίβας
- ΒΑΛΕ(χ)
- το χ προστίθεται στη στοίβα
- ΒΓΑΛΕ
- ένα στοιχείο αφαιρείται από τη στοίβα
- ΑΦΗΣΕ
- η στοίβα δε μεταβάλλεται
- υποεντολή εισόδου
- ΠΡΟΧΩΡΑ
- διάβασε ένα νέο στοιχείο από την είσοδο
- ΚΡΑΤΑ
- κράτα το υπάρχον στοιχείο εισόδου
- υποεντολή επόμενης κατάστασης
- ΚΑΤΑΣΤΑΣΗ(S)
- η νέα κατάσταση είναι η S
Παράσταση κινήσεων
Κάθε εντολή κίνησης έχει τη μορφή:
δ(σ1, σ2, σ3) = (Σ1, Σ2, Σ3)
όπου:
- σ1
- η κατάσταση του ΑΣ,
- σ2
- το σύμβολο στην κορυφή της στοίβας,
- σ3
- το σύμβολο εισόδου,
- Σ1
- η υποεντολή της στοίβας,
- Σ2
- η υποεντολή εισόδου,
- Σ3
- η υποεντολή επόμενης κατάστασης.
Αν δεν προσδιορίζεται μια εντολή τότε αυτή υπονοείται ως εξής:
- υποεντολή της στοίβας:
- ΑΦΗΣΕ
- η στοίβα δε μεταβάλλεται
- υποεντολή εισόδου:
- ΠΡΟΧΩΡΑ
- διάβασε ένα νέο στοιχείο από την είσοδο
- υποεντολή επόμενης κατάστασης:
- ΚΑΤΑΣΤΑΣΗ(S)
- η νέα κατάσταση είναι η τωρινή
Λειτουργία
- Το ΑΣ αρχικά:
- τοποθετεί το αρχικό σύμβολο της στοίβας στην κορυφή της στοίβας
- θέτει ως κατάσταση την αρχική κατάσταση
- διαβάζει ένα σύμβολο από την είσοδο
- Στη συνέχεια εκτελεί διαδοχικές κινήσεις
- Τερματίζει τη λειτουργία του όταν:
- διαβάσει όλα τα σύμβολα εισόδου ή
- δεν ορίζεται μια κίνηση
Αν ένα ΑΣ
- διαβάσει όλα τα σύμβολα εισόδου και
- η στοίβα περιέχει μόνο το αρχικό της σύμβολο
τότε θεωρούμε πως το ΑΣ αναγνώρισε τη συμβολοσειρά εισόδου.
Ένα ΜΑΣ όταν φτάσει σε στάδιο που δεν ορίζεται κίνηση οπισθοδρομεί
μέχρι ένα στάδιο που να μπορέσει να εκτελέσει μια εναλλακτική κίνηση.
Παράδειγμα
Ορίζουμε ένα αυτόματο
Μ = (Κ, Σ, Γ, δ, q0, Z0)
ως εξής:
- Κ
- {Α}
- Σ
- {'(', ')'}
- Γ
- {Χ, I}
- Δ
- {
- δ(Α, Ι, '(') = (ΒΑΛΕ(Ι))
- δ(Α, Χ, '(') = (ΒΑΛΕ(Ι))
- δ(Α, Ι, ')') = (ΒΓΑΛΕ)
}
- q0
- A
- Z0
- X
Το αυτόματο αυτό αναγνωρίζει ζυγισμένα ζευγάρια παρενθέσεων.
Γραμματική
Τη σύνταξη των γλωσσών την ορίζουμε με γραμματικές.
Μια γραμματική ορίζεται από την τετράδα:
G = (VN, VT, P, S):
- VN
- αλφάβητο με τα μη τερματικά σύμβολα (non-terminal symbols).
- VT
- αλφάβητο με τα τερματικά σύμβολα (terminal symbols).
- P
- συντακτικοί κανόνες (syntax rules) που αποτελούνται
από ζευγάρια (α, β) που συμβολίζονται α -> β.
Το α αποτελείται από ένα σύμβολο ενώ το β από μια ακολουθία συμβόλων.
- S
- Το αρχικό μη τερματικό σύμβολο εκκίνησης.
Από μια γραμματική μπορούμε να παράξουμε συμβολοσειρές αρχίζοντας
από το σύμβολο εκκίνισης με διαδοχικές εφαρμογές των συντακτικών κανόνων.
Κάθε εφαρμογή αντικαθιστά ένα σύμβολο που βρίσκεται στα αριστερά ενός
συντακτικού κανόνα με τα αντίστοιχα σύμβολα που βρίσκονται δεξιά.
Με τον τρόπο αυτό μπορούμε να καταλήξουμε σε μια συμβολοσειρά από τερματικά
σύμβολα.
Η συμβολοσειρά αυτή ανήκει στη γλώσσα που ορίζεται από την αντίστοιχη γραμματική.
Η διαδικασία δημιουργίας της συμβολοσειράς από τη
γραμματική ονομάζεται παραγωγή (derivation).
Παράδειγμα
G = (VN, VT, P, S):
- VN
- {SUM, PROD, NUM}
- VT
- {0, 1, +, *}
- P
- {
- NUM ->1,
- NUM ->0,
- SUM -> SUM + PROD
- SUM -> PROD
- PROD -> PROD * NUM
- PROD -> NUM
}
- S
- SUM
Συντακτικό δένδρο
- Μια παραγωγή μπορεί να παρασταθεί από ένα
συντακτικό δένδρο (syntax tree).
- Η κορυφή του δένδρου είναι το αρχικό σύμβολο.
- Τα φύλλα του δένδρου περιέχουν τα τερματικά σύμβολα της συμβολοσειράς.
- Οι εσωτερικοί κόμβοι του δένδρου αντιστοιχούν στους κανόνες της
γραμματικής.
- Ο πατέρας κάθε κόμβου αποτελεί το δεξί μέρος του κανόνα.
Παράδειγμα
SUM
PROD + 0
1 * 0
Ιεραρχία γραμματικών
Ανάλογα με τους συντακτικούς κανόνες που περιέχει μια γραμματική
ορίζεται η ιεραρχία γραμματικών του Chomsky
- Τύπου 0: ελεύθερη
-
με κανόνες της μορφής σ->τ όπου:
- Τύπου 1: γραμματική με συμφραζόμενα (context sensitive grammar)
-
με κανόνες της μορφής μΑν->μχν όπου:
- μ, ν ανήκουν V*
- χ ανήκει V+
- Α ανήκει VN
- Τύπου 2: γραμματική χωρίς συμφραζόμενα (context free grammar)
-
με κανόνες της μορφής Α->χ όπου:
Οι γραμματικές αυτές μπορούν να ορίσουν συχνά τη σύνταξη μιας γλώσσας.
- Τύπου 3: κανονική γραμματική (regular grammar)
-
με κανόνες της μορφής Α->α ή Α->αΒ όπου:
- χ ανήκει V*
- Α, Β ανήκουν VN
- α ανήκει VΤ ή είναι το κενό σύμβολο
Οι γραμματικές αυτές μπορούν να ορίσουν συχνά τα λεκτικά στοιχεία μιας γλώσσας.
Συμβολισμός EBNF
Ο συμβολισμός EBNF (Extended Backus-Naur Form) μας επιτρέπει να ορίσουμε
με περιεκτικό τρόπο μια γραμματική:
- Τα τερματικά σύμβολα περικλείονται σε μονά εισαγωγικά.
- Οι συντακτικοί κανόνες τελειώνουν με .
- Η παραγωγή συμβολίζεται με ::=
- παραγωγή Α ή Β ως: Α | Β
- προαιρετικά στοιχεία ως: [Α]
- επανάληψη μία ή περισσότερες φορές ως: Α+
- επανάληψη καμία ή περισσότερες φορές ως: Α*
- παρενθέσεις επιτρέπουν τον ορισμό της σειράς παραγωγής
Παράδειγμα
expr ::= term ('+' term |'-' term) *
term ::= factor ('*' factor |'/' factor) *
factor ::= digit | '-' factor | '(' expr ')'
digit ::= '0' | '1' | '2' | '3' |'4' | '5' | '6' | '7' | '8' | '9'
Ασκήσεις
- Να ορίσετε σε EBNF τη σύνταξη του ορισμού δομών (structure) της C.
Βιβλιογραφία
Συντακτική ανάλυση
Ο συντακτικός αναλυτής
Ο συντακτικός αναλυτής:
- υλοποιεί τη συντακτική ανάλυση μιας συγκεκριμένης γλώσσας,
- δέχεται ως είσοδο ένα πρόγραμμα με τη μορφή ακολουθίας λεκτικών
μονάδων,
- ελέγχει αν το πρόγραμμα είναι σύμφωνο με τη γραμματική
της γλώσσας που υλοποιεί (αν ανήκει στη συγκεκριμένη γλώσσα),
- σε περίπτωση συντακτικού λάθους ενημερώνει το χρήστη,
- παράγει το συντακτικό δένδρο που αντιστοιχεί στην ακολουθία εισόδου.
Τρόποι υλοποίησης
Διαχωρίζουμε δύο είδη συντακτικών αναλυτών ανάλογα με τον τρόπο
που σχηματίζουν το δένδρο:
- Συντακτικός αναλυτής από πάνω προς τα κάτω (top down parser)
- ο αναλυτής αυτός ξεκινά από τη ρίζα του δένδρου και αντικαθιστά
μη τερματικά σύμβολα από το αριστερό τμήμα παραγωγών με τα αντίστοιχα
δεξιά τους τμήματα μέχρι να αναγνωρίσει όλη την είσοδο.
Το μη τερματικό σύμβολο που επιλέγεται για αντικατάσταση είναι κάθε φορά το
αριστερότερο (leftmost) (L) μη τερματικό σύμβολο.
Ακόμα, ο αναλυτής για να μπορέσει να υλοποιηθεί πρέπει να αρκεί να
διαβάζει κάθε φορά ένα (1) μόνο σύμβολο από την είσοδο
από αριστερά προς τα δεξιά (L).
Έτσι ο αναλυτής και η αντίστοιχη γραμματική ονομάζονται LL(1).
Ο αναλυτής αυτός μπορεί να υλοποιηθεί είτε ως ένας
συντακτικός αναλυτής αναδρομικής κατάβασης (recursive descent parser)
ή ως ένα ειδικό αυτόματο στοίβας.
Ο συντακτικός αναλυτής αναδρομικής κατάβασης αποτελείται από συναρτήσεις,
μια για κάθε μη τερματικό σύμβολο,
που καλούν η μια την άλλη.
Το ρόλο της στοίβας παίζει η στοίβα κλήσεων των συναρτήσεων που υλοποιεί ο
επεξεργαστής.
Για το λόγο αυτό οι συντακτικοί αυτοί αναλυτές είναι συχνά γρηγορότεροι
από αυτούς που υλοποιούνται με αυτόματα.
- Συντακτικός αναλυτής από κάτω προς τα πάνω (bottom up parser)
- ο αναλυτής αυτός αντικαθιστά δεξιά τμήματα παραγωγών με τα
αντίστοιχα αριστερά τους τμήματα.
Ο αναλυτής αυτός χρησιμοποιεί κάθε φορά τη δεξιότερη (rightmost)
παραγωγή.
Ανάλογα με το αν χρειάζεται να εξετάσει 0, 1 ή Κ σύμβολα εισόδου για να
υλοποιήσει μια παραγωγή ονομάζεται LR(0), LR(1) ή LR(K).
Η υλοποίηση του αναλυτή αυτού γίνεται από ειδικό αυτόματο στοίβας.
Και στις δύο περιπτώσεις οι γραμματικές πρέπει να εκπληρούν ορισμένους
κανόνες για να μπορούν να σχηματίσουν τον αντίστοιχο συντακτικό αναλυτή
και κατηγοριοποιούνται ανάλογα με το όνομα του αναλυτή (LL(1), LR(1), ...).
Αναλυτής αναδρομικής κατάβασης
- Ο συντακτικός αναλυτής αναδρομικής κατάβασης υλοποιεί μια συνάρτηση
για κάθε κανόνα της γραμματικής.
- Η κάθε συνάρτηση:
- Για τα μη τερματικά σύμβολα του κανόνα καλεί την αντίστοιχη
συνάρτηση.
- Διαβάζει τα τερματικά σύμβολα του κανόνα από το λεκτικό αναλυτή.
- Αν διαβάσει ένα τερματικό σύμβολο που δεν αντιστοιχεί στον
κανόνα το σπρώχνει πίσω στην είσοδο (ungetch()) και επιστρέφει.
- Αν έχει να επιλέξει ανάμεσα σε διαφορετικές παραγωγές για έναν
κανόνα, διαβάζει ένα σύμβολο εισόδου και αποφασίζει ανάλογα
με αυτό.
Παράδειγμα
Ο παρακάτω συντακτικός αναλυτής ελέγχει για τον αν η είσοδός του
ανήκει στη γλώσσα που ορίζεται από την παρακάτω γραμματική EBNF:
expr ::= term ('+' term |'-' term) *
term ::= factor ('*' factor |'/' factor) *
factor ::= digit | '-' factor | '(' expr ')'
digit ::= 0 | 1 | 2 | 3 |4 | 5 | 6 | 7 | 8 | 9
και τυπώνει "Parse ok", ") expected" ή "Syntax error".
/*
* Recursive descent parser for the following expression grammar:
* expr ::= term ('+' term |'-' term) *
* term ::= factor ('*' factor |'/' factor) *
* factor ::= digit | '-' factor | '(' expr ')'
* digit ::= 0 | 1 | 2 | 3 |4 | 5 | 6 | 7 | 8 | 9
*
* D. Spinellis, November 1999
*
* $Id: parse0.c 1.1 1999/11/10 00:14:12 dds Exp dds $
*
*/
#include <stdio.h>
/* Forward declarations */
void term(void);
void factor(void);
/* expr ::= term ('+' term |'-' term) * */
void
expr(void)
{
int c;
term();
for (;;) {
switch (c = getchar()) {
case '+':
term();
break;
case '-':
term();
break;
default:
ungetc(c, stdin);
return;
}
}
}
/* term ::= factor ('*' factor |'/' factor) * */
void
term(void)
{
int c;
factor();
for (;;) {
switch (c = getchar()) {
case '*':
factor();
break;
case '/':
factor();
break;
default:
ungetc(c, stdin);
return;
}
}
}
/* factor ::= digit | '-' factor | '(' expr ')' */
void
factor(void)
{
int c;
switch (c = getchar()) {
case '0': case '1': case '2': case '3': case '4':
case '5': case '6': case '7': case '8': case '9':
return;
case '-':
factor();
;
case '(':
expr();
c = getchar();
if (c != ')') {
printf("Expected ')'\n");
exit(1);
}
return;
default:
printf("Syntax error\n");
exit(1);
}
}
/*
* Test harness
*/
main()
{
expr();
printf("Parse ok\n");
}
Χρήση του αναλυτή
% parse
1+2*4-7*(3-1)
Parse ok
% parse
3++3-3
Syntax error
% parse
3-2*(2+2
Expected ')'
% parse
2-
Syntax error
Παράσταση του συντακτικού δένδρου
- Το συντακτικό δένδρο που δημιουργεί ο συντακτικός αναλυτής
παριστάνεται συχνά ως μια δενδρική δομή.
- Κάθε κόμβος του δένδρου πρέπει να περιέχει κάποιο στοιχείο για
το είδος του και τα παιδιά του.
- Ένας συνηθισμένος τρόπος υλοποίησης στη C περιλαμβάνει:
- τον ορισμό απαρίθμησης για τα είδη των κόμβων
- τον ορισμό μιας κοινής δομής για όλους τους κόμβους
- τον ορισμό μέσα στη δομή μιας ένωσης για τις διαφορές
ανάμεσα στους κόμβους
- τη χρήση δεικτών για την παράσταση των συνδέσεων ανάμεσα στους
γονείς και τα παιδιά.
- Συχνά ορίζουμε ειδικές συναρτήσεις για τη δημιουργία τμημάτων του
δένδρου.
Παράδειγμα ορισμού (tree.h)
/*
* Tree type and building function declarations
*
* D. Spinellis, November 1999
*
* $Id: tree.h 1.1 1999/11/09 23:32:12 dds Exp $
*
*/
enum e_nodetype {
ent_binop, /* Binary operator expr */
ent_unop, /* Unary operator expr */
ent_digit /* Digit expr */
};
struct s_tree {
enum e_nodetype nt; /* Expression type */
union {
struct s_binop {
struct s_tree *left, *right;
char op;
} binop; /* Binary operator expr */
struct s_unary {
struct s_tree *expr;
char op;
} unop; /* Unary operator expr */
int digit; /* Digit expression */
} u;
};
struct s_tree * mk_binop(struct s_tree *left, char op, struct s_tree *right);
struct s_tree * mk_unop(char op, struct s_tree *expr);
struct s_tree * mk_digit(char c);
Παράδειγμα συναρτήσεων δημιουργία και εκτύπωσης (tree.c)
/*
* Tree building functions
*
* D. Spinellis, November 1999
*
* $Id: tree.c 1.2 1999/11/10 09:15:35 dds Exp $
*
*/
#include <stdlib.h>
#include "tree.h"
struct s_tree *
mk_binop(struct s_tree *left, char op, struct s_tree *right)
{
struct s_tree *t = malloc(sizeof(struct s_tree));
t->nt = ent_binop;
t->u.binop.left = left;
t->u.binop.op = op;
t->u.binop.right = right;
return (t);
}
struct s_tree *
mk_unop(char op, struct s_tree *expr)
{
struct s_tree *t = malloc(sizeof(struct s_tree));
t->nt = ent_unop;
t->u.unop.op = op;
t->u.unop.expr = expr;
return (t);
}
struct s_tree *
mk_digit(char c)
{
struct s_tree *t = malloc(sizeof(struct s_tree));
t->nt = ent_digit;
t->u.digit = c -'0';
return (t);
}
/*
* Indent output by the indent ammount given
*/
static void
indent(int level)
{
int i;
for (i = 0; i < level; i++)
printf(" ");
}
/*
* Dump an expression tree to the standard output
*/
void
dumptree(struct s_tree *t)
{
static int il = 0; /* Indent level */
il++;
switch (t->nt) {
case ent_binop:
dumptree(t->u.binop.left);
indent(il); printf("%c\n", t->u.binop.op);
dumptree(t->u.binop.right);
break;
case ent_unop:
indent(il); printf("%c\n", t->u.unop.op);
dumptree(t->u.unop.expr);
break;
case ent_digit:
indent(il); printf("%d\n", t->u.digit);
break;
}
il--;
}
Δημιουργία συντακτικού δένδρου
Για να κάνουμε έναν συντακτικό αναλυτή αναδρομικής καθόδου
να δημιουργήσει το συντακτικό δένδρο, φροντίζουμε κάθε συνάρτηση
του αναλυτή να επιστρέφει τον αντίστοιχο κλάδο του δένδρου.
Το παρακάτω παράδειγμα δημιουργεί και τυπώνει ένα συντακτικό δένδρο για τη
γραμματική που εξετάζουμε:
/*
* Recursive descent parser for the following expression grammar:
* expr ::= term ('+' term |'-' term) *
* term ::= factor ('*' factor |'/' factor) *
* factor ::= digit | '-' factor | '(' expr ')'
* digit ::= 0 | 1 | 2 | 3 |4 | 5 | 6 | 7 | 8 | 9
*
* D. Spinellis, November 1999
*
* $Id: parse.c 1.1 1999/11/09 23:32:12 dds Exp $
*
*/
#include <stdio.h>
#include "tree.h"
/* Forward declarations */
struct s_tree *term(void);
struct s_tree *factor(void);
/* expr ::= term ('+' term |'-' term) * */
struct s_tree *
expr(void)
{
struct s_tree *e1, *e2;
int c;
e1 = term();
for (;;) {
switch (c = getchar()) {
case '+':
e2 = term();
e1 = mk_binop(e1, '+', e2);
break;
case '-':
e2 = term();
e1 = mk_binop(e1, '-', e2);
break;
default:
ungetc(c, stdin);
return (e1);
}
}
}
/* term ::= factor ('*' factor |'/' factor) * */
struct s_tree *
term(void)
{
struct s_tree *t1, *t2;
int c;
t1 = factor();
for (;;) {
switch (c = getchar()) {
case '*':
t2 = factor();
t1 = mk_binop(t1, '*', t2);
break;
case '/':
t2 = factor();
t1 = mk_binop(t1, '/', t2);
break;
default:
ungetc(c, stdin);
return (t1);
}
}
}
/* factor ::= digit | '-' factor | '(' expr ')' */
struct s_tree *
factor(void)
{
struct s_tree *f;
int c;
switch (c = getchar()) {
case '0': case '1': case '2': case '3': case '4':
case '5': case '6': case '7': case '8': case '9':
return (mk_digit((char)c));
case '-':
f = factor();
return (mk_unop('-', f));
case '(':
f = expr();
c = getchar();
if (c != ')')
printf("Expected ')'\n");
return (f);
}
}
/*
* Test harness
*/
main()
{
struct s_tree *t;
t = expr();
dumptree(t);
}
Παράδειγμα χρήσης
Με τις παρακάτω εντολές βλέπουμε το συντακτικό δένδρο της έκφρασης
1+2*(4-5)*-3 :
% echo 1+2*(4-5)*-3 | parse
1
+
2
*
4
-
5
*
-
3
Ασκήσεις
- Να υλοποιήσετε σε C ένα συντακτικό αναλυτή που να αναγνωρίζει και
να τυπώνει το συντακτικό δένδρο για αριθμητικές εκφράσεις που αποτελούνται
από ψηφία, +, -, *, /, (, ), ^ (ύψωση σε δύναμη) σύμφωνα με τους
συνηθισμένους κανόνες προτεραιότητας της αριθμητικής.
Βιβλιογραφία
- Alfred V. Aho, Ravi Sethi,
and Jeffrey D. Ullman.
Compilers, Principles, Techniques, and Tools, pages 159–246.
Addison-Wesley, 1985.
- Francis Giannesini
and Jacques Cohen.
Parser generation and grammar manipulation using Prolog's infinite trees.
Journal of Logic Programming, 1(3):253–265, October 1984.
- David H. D. Warren.
Logic programming and compiler writing.
Software: Practice & Experience, 10:97–125, 1980.
Το μεταεργαλείο yacc
Το μεταεργαλείο yacc
- Το μεταεργαλείο yacc επιτρέπει την αυτόματη δημιουργία
γλωσσικών επεξεργαστών και συντακτικών αναλυτών.
- Ως είσοδο δέχεται μια γραμματική BNF σε μορφή κατάλληλη για
μηχανική επεξεργασία καθώς και σημασιολογικούς κανόνες.
- Ως έξοδο παράγει κώδικα που επεξεργάζεται τα τερματικά σύμβολα
που δέχεται στην είσοδό του και εκτελεί του σημασιολογικούς κανόνες
για τις γραμματικές προτάσεις που αναγνωρίζει.
- Η λειτουργία του κώδικα που παράγει βασίζεται σε ένα πεπερασμένο
αυτόματο στοίβας επαυξημένο με ειδικούς κανόνες για αιτιοκρατική λειτουργία.
- Το μεταεργαλείο yacc συνεργάζεται άριστα με το μεταεργαλείο lex για
τη λεκτική ανάλυση.
Διαδικασία χρήσης
- Το αρχείο εισόδου για το εργαλείο yacc έχει κατάληξη .y
- Το αρχείο εισόδου περιέχει δηλωτική περιγραφή της γραμματικής
που θα αναγνωρίσει ο συντακτικός αναλυτής καθώς και σημασιολογικούς
κανόνες.
- Το εργαλείο yacc (με παραμέτρους -vd και το όνομα του αρχείου)
διαβάζει το αρχείο αυτό και δημιουργεί:
- ένα αρχείο σε C με όνομα y.tab.c που υλοποιεί το
συντακτικό αναλυτή που προδιαγράψαμε.
- ένα αρχείο επικεφαλίδας σε C με όνομα y.tab.h που ορίζει
σταθερές για το λεκτικά (τερματικά) σύμβολα.
- ένα αρχείο κειμένου με όνομα y.output που επεξηγεί τις καταστάσεις
και τις μεταπτώσεις του αυτομάτου.
- Ο σαρωτής είναι υλοποιημένος στη συνάρτηση yyparse().
- Κατά τη λειτουργία του ο συντακτικός αναλυτής καλεί τη συνάρτηση yylex()
για να λάβει το επόμενο λεκτικό σύμβολο.
- Για τη λειτουργία του συντακτικού αναλυτή τυπικά καλούμε τη συνάρτηση
yyparse() μέσω της συνάρτησης main() την οποία υλοποιούμε εμείς.
Σημείωση
Στο εργαστήριο θα χρησιμοποιηθεί το πρόγραμμα bison που είναι συμβατό υπερσύνολο
του yacc.
Αρχείο εισόδου
Δηλώσεις του yacc
Οι δηλώσεις του yacc μας επιτρέπουν να ορίσουμε:
- Συμβολικές τιμές για τα τερματικά σύμβολα με τη δήλωση %token:
%token tINC, tDEC, tFOR, tWHILE, tELSE
- Την προτεραιότητα και την προσεταιριστικότητα των τελεστών με τις
δηλώσεις:
- %left τερματικό σύμβολο ...
- προσεταιριστικότητα από αριστερά προς τα δεξιά.
Α τελ Β τελ Γ είναι (Α τελ Β) τελ Γ.
- %right τερματικό σύμβολο ...
- προσεταιριστικότητα από δεξιά προς τα αριστερά.
Α τελ Β τελ Γ είναι Α τελ (Β τελ Γ).
- %nonassoc τερματικό σύμβολο ...
- μη προσεταιριστικότητα.
Α τελ Β τελ Γ εμφανίζει μήνυμα λάθους
Η προτεραιότητα ορίζεται από σειρά εμφάνισης με τους τελεστές στις πρώτες
δηλώσεις να έχουν τη χαμηλότερη.
Παράδειγμα:
%left '+' '-'
%left '*' '/' '%'
%left '.'
%right '^'
%left UMINUS
- Τους τύπους των πιθανών σημασιολογικών τιμών που μπορούν να συσχετιστούν
με τερματικά και μη σύμβολα με τη δήλωση %union.
Παράδειγμα:
%union {
double d;
struct s_vec {double x, y;} v;
char *s;
double (*f)(double);
double (*f2)(double, double);
double (*f2i)(int, double);
};
- Τον τύπο των μη τερματικών συμβόλων με τη δήλωση %type .
Ο τύπος typename πρέπει να είναι κάποιο μέλος της ένωσης %union.
Παράδειγμα:
%type <s> optasg
%type <d> scalar
%type <v> vector
- Τους τύπους των τερματικών συμβόλων με τη χρήση του στις
δηλώσεις %token, %left, %right:
Παράδειγμα:
%token <d> tNUM
%token <s> tVAR
%token <v> tVEC
%left <c> '+' '-'
- Το σύμβολο αρχής με τη δήλωση %start symbol.
Παράδειγμα:
%start program
Συντακτικοί κανόνες
- Οι συντακτικοί κανόνες (syntax rules) γράφονται σε
μορφή BNF με την παρακάτω σύνταξη:
name1 : symbol01 symbol02 symbol03 ... /* Alternative 1 */
| symbol11 symbol12 ... /* Alternative 2 */
| symbol21 symbol22 symbol23 ... /* Alternative 3 */
;
name2 : ...
- Κάθε κανόνας ορίζει μια σειρά από παραγωγές για το αντίστοιχο μη
τερματικό σύμβολο.
- Τα σύμβολα δεξιά του κανόνα μπορεί να είναι τερματικά ή μη τερματικά.
- Επιτρέπεται η διατύπωση εναλλακτικών κανόνων με το ίδιο όνομα ή
ο χωρισμός των παραγωγών με το σύμβολο |.
- Η επανάληψη ορίζεται με τη χρήση αναδρομής.
- Καλό είναι, για να μη δημιουργείται κατά τη μεταγλώττιση μεγάλη
στοίβα στο αυτόματο του yacc να χρησιμοποιούμε αριστερή αναδρομή και όχι
δεξιά αναδρομή (ο κανόνας δηλαδή να εμφανίζεται αναδρομικά στο αριστερό μέρος
της παραγωγής και όχι στο δεξιό).
Παράδειγμα αριστερής αναδρομής (ορθή χρήση):
expseq1: exp
| expseq1 ',' exp
;
Παράδειγμα δεξιάς αναδρομής (να αποφεύγεται):
expseq1: exp
| exp ',' expseq1
Τερματικά και μη τερματικά σύμβολα
- Τα τερματικά σύμβολα του yacc πρέπει να οριστούν με τη χρήση της
δήλωσης %token.
- Επίσης είναι δυνατή η χρήση απλών χαρακτήρων ως τερματικά σύμβολα
γράφοντάς τους σε μονά εισαγωγικά: 'c'
- Για κάθε τερματικό σύμβολο που ορίζεται στο αρχείο .y ο yacc δημιουργεί
μια δήλωση σταθεράς (#define) στο αρχείο y.tab.h για να μπορέσει ο
λεκτικός αναλυτής να επιστρέψει την ίδια τιμή.
Παράδειγμα:
- Για να είναι δυνατός ο ορισμός παραγωγών με αμοιβαία αναδρομή τα μη
τερματικά σύμβολα μπορούν να χρησιμοποιηθούν πριν οριστούν από κάποιο κανόνα.
Τιμές των συμβόλων
Σημασιολογικοί κανόνες
Απλό παράδειγμα
Το παρακάτω πρόγραμμα υλοποιεί μια απλή αριθμομηχανή.
/* Infix notation calculator--calc */
%{
#define YYSTYPE double
#include <math.h> /* Needed for pow */
%}
/* YACC Declarations */
%token NUM
%left '-' '+'
%left '*' '/'
%left NEG /* negation--unary minus */
%right '^' /* exponentiation */
/* Grammar follows */
%%
input: /* empty string */
| input line
;
line: '\n'
| exp '\n' { printf ("\t%.10g\n", $1); }
;
exp: NUM { $$ = $1; }
| exp '+' exp { $$ = $1 + $3; }
| exp '-' exp { $$ = $1 - $3; }
| exp '*' exp { $$ = $1 * $3; }
| exp '/' exp { $$ = $1 / $3; }
| '-' exp %prec NEG { $$ = -$2; }
| exp '^' exp { $$ = pow ($1, $3); }
| '(' exp ')' { $$ = $2; }
;
%%
#include <ctype.h>
#include <stdio.h>
/* Lexical analyzer */
int
yylex ()
{
int c;
/* skip white space */
while ((c = getchar ()) == ' ' || c == '\t')
;
/* process numbers */
if (c == '.' || isdigit (c)) {
ungetc (c, stdin);
scanf ("%lf", &yylval);
return NUM;
}
/* return end-of-file */
if (c == EOF)
return 0;
/* return single chars */
return c;
}
main ()
{
yyparse();
}
/* error function */
void
yyerror (char *s) /* Called by yyparse on error */
{
printf("%s\n", s);
}
Μεταγλώττιση και χρήση
Η διαδικασία μεταγλώττισης και χρήσης του αρχείου της αριθμομηχανής
(αν έχει ονομαστεί calc.y) φαίνεται από τις παρακάτω εντολές:
$ yacc -vd calc.y
$ ls -rtl
total 23
-rw-r--r-- 1 dspin users 1304 Nov 16 22:51 calc.y
-rw-r--r-- 1 dspin users 32 Nov 16 22:51 y.tab.h
-rw-r--r-- 1 dspin users 12078 Nov 16 22:51 y.tab.c
-rw-r--r-- 1 dspin users 3773 Nov 16 22:51 y.output
$ cc -o calc y.tab.c -lm
$ ./calc
1+2*3
7
3*(1+2)
9
sdkjfh
syntax error
$
Τρόπος λειτουργίας
Το παρακάτω απόσπασμα από το αρχείο y.output απεικονίζει μια κατάσταση,
τους κανόνες που είναι υποψήφιοι για αναγνώριση (τι βρίσκεται στη στοίβα),
και τις ενέργειες ανάλογα με το σύμβολο που θα διαβαστεί:
state 17
exp : exp . '+' exp (6)
exp : exp . '-' exp (7)
exp : exp '-' exp . (7)
exp : exp . '*' exp (8)
exp : exp . '/' exp (9)
exp : exp . '^' exp (11)
'*' shift 12
'/' shift 13
'^' shift 14
'-' reduce 7
'+' reduce 7
'\n' reduce 7
')' reduce 7
Ασκήσεις
- Να υλοποιήσετε με το μεταεργαλείο yacc έναν υπολογιστή που να
επεξεργάζεται διανύσματα (δύο διαστάσεων) με:
- τους δυαδικούς τελεστές σε διανύσματα + -
- το μοναδικό τελεστή -
- τους τελεστές μεταξύ διανύσματος και σταθεράς * /
- παρενθέσεις
Το κάθε διάνυσμα θα μπορεί να γράφεται ως [χ, ψ].
Κάθε γραμμή εισόδου θα αποτελεί μια εντολή για πράξη.
Παράδειγμα:
[1, 2]
Result = [1, 2]
[1, 1] + [1, 2]
Result = [2, 2]
-([1, 2] * 2 + [1, 1])
Result = [-3, -5]
Βιβλιογραφία
- Alfred V. Aho, Ravi Sethi,
and Jeffrey D. Ullman.
Compilers, Principles, Techniques, and Tools, pages 257–267.
Addison-Wesley, 1985.
- Free
Software Foundation.
Bison — the
YACC-compatible parser generator.
Available online: http://www.gnu.org/manual/flex-2.5.4/flex.html, November
1995.
- Stephen C. Johnson
and Michael E. Lesk.
Language development tools.
Bell System Technical Journal, 56(6):2155–2176, July-August
1987.
- Stephen C. Johnson.
Yacc — yet another compiler-compiler.
Computer Science Technical Report 32, Bell Laboratories, Murray Hill, NJ, USA,
July 1975.
- John Levine, Tony Mason,
and Doug Brown.
Lex and Yacc.
O'Reilly & Associates, second edition, 1992.
Πίνακες συμβόλων
Λειτουργία
Οι λειτουργίες που θέλουμε να εκτελούμε σε έναν πίνακα συμβόλων
περιλαμβάνουν:
- Την προσθήκη ενός νέου συμβόλου.
- Την ενημέρωση των πληροφοριών που σχετίζονται με ένα σύμβολο.
- Την ανάκτηση των πληροφοριών που σχετίζονται με ένα σύμβολο.
- Την αλλαγή του πεδίου ορατότητας των συμβόλων.
- Τη διαγραφή ενός συμβόλου.
Περιεχόμενα
Τα στοιχεία που θέλουμε να αποθηκεύσουμε για κάθε σύμβολο είναι:
- Τη συμβολοσειρά που το παριστάνει.
- Το πεδίο ονομάτων στο οποίο ανήκει. Για παράδειγμα στη
γλώσσα C το ίδιο σύμβολο μπορεί να χρησιμοποιηθεί ταυτόχρονα
στα παρακάτω πεδία ονομάτων:
- συναρτήσεις, ονομάτα typedef, μεταβλητές και σταθερές enum
- ετικέτες εντολών
- ετικέτες δομών, ενώσεων και απαριθμήσεων
- τα μέλη κάθε ξεχωριστής δομής ή ένωσης
- Το είδος του. Για παράδειγμα στη C το είδος μπορεί να είναι ένα από τα
παρακάτω:
- συναρτήση,
- όνομα typedef,
- μεταβλητή
- σταθερά enum
- ετικέτα εντολών
- ετικέτα δομής
- ετικέτα ένωσης
- ετικέτα απαρίθμησης
- μέλος συγκεκριμένης δομής ή ένωσης
- Ο τύπος του
- Πρόσθετα στοιχεία που σχετίζονται με τον τύπο του όπως:
- τις διαστάσεις του πίνακα
- τα ονόματα μελών της δομής ή ένωσης
- τα μέλη μιας κλάσης
- Το αρχείο και τη γραμμή που έχει δηλωθεί και οριστεί.
Δομές
Ένας πίνακας συμβόλων είναι πολύ βολικό να σχεδιαστεί ως ένας
αφηρημένος τύπος δεδομένων ή ως μια κλάση.
Με τον τρόπο αυτό:
- εσωτερικές αλλαγές στον τρόπο οργάνωσής του
δε θα επηρεάσουν τον κώδικα του υπόλοιπου μεταγλωττιστή.
- διαφορετικά πεδία ονομάτων ορίζονται εύκολα ως διαφορετικοί
πίνακες συμβόλων.
Δομές κατάλλληλες για τη φύλαξη των συμβόλων είναι οι παρακάτω:
- Συνδεδεμένη λίστα ή πίνακας
-
Κατάλληλη μόνο για πίνακες με πολύ μικρό αριθμό συμβόλων (π.χ.
τα μέλη μιας δομής)
- Πίνακας κατακερματισμού
-
Γρήγορος στην εισαγωγή και αναζήτηση, αλλά απαιτεί προσεκτικό σχεδιασμό της συνάρτησης
κατακερματισμού και πρόβλεψη για περιπτώσεις συγκρούσεων.
Μπορεί να οδηγήσει σε σπατάλη μνήμης.
- Δυαδικό δένδρο
-
Σχετικά γρήγορο στην εισαγωγή και αναζήτηση με μικρές απαιτήσεις μνήμης.
Εμβέλεια ονομάτων
Κάθε αναζήτηση στον πίνακα συμβόλων πρέπει να γίνεται σύμφωνα με τους
κανόνες εμβέλειας ορατότητας της γλώσσας.
Αυτό σημαίνει πως για το σύμβολο που γίνεται η αναζήτηση πρέπει
να βρεθεί το πιο εσωτερικό ορατό σύμβολο με το ίδιο όνομα.
Δύο πιθανοί τρόποι οργάνωσης είναι οι παρακάτω:
- η χρήση στοίβας από ενεργούς πίνακες συμβόλων που αντιστοιχεί στις
ενότητες (block) που είναι ενεργά κάθε στιγμή,
- η κατάλληλη αρίθμηση των ενοτήτων και των αντιστοίχων πινάκων
συμβόλων.
Βιβλιογραφία
Παραγωγή κώδικα
Εισαγωγή
Η παραγωγή κώδικα αποτελεί το πιο ενδιαφέρον και σύνθετο στάδιο της
μεταγλώττισης.
Κατά το στάδιο αυτό μπορούν να υλοποιηθούν τεχνικές βελτιστοποίησης
προσανατολισμένες στη συγκεκριμένη γλώσσα ή αρχιτεκτονική και να
υλοποιηθούν αλγόριθμοι βέλτιστης χρήσης των στοιχείων της αρχιτεκτονικής.
Η παραγωγή του τελικού εκτελέσιμου
κώδικα μπορεί να διακριθεί στα παρακάτω στάδια:
Παραγωγή ενδιάμεσου κώδικα
Ο ενδιάμεσος κώδικας είναι ένας τρόπος παράστασης του προγράμματος
κοντά σε υπάρχουσες αρχιτεκτονικές υπολογιστών που παράγεται από το συντακτικό
δένδρο.
Οι λόγοι που το συντακτικό δένδρο μετασχηματίζεται σε ενδιάμεσο κώδικα
και όχι κατευθείαν σε κώδικα μηχανής είναι οι παρακάτω:
- η μετάφραση σε κώδικα μηχανής από το συντακτικό δένδρο είναι πολύ
πιο δύσκολη απ' ότι από ενδιάμεσο κώδικα,
- το τμήμα του μεταγλωττιστή που περιλαμβάνει μέχρι και τη δημιουργία
του ενδιάμεσου κώδικα είναι ανεξάρτητο από την αρχιτεκτονική του τελικού
επεξεργαστή και μπορεί να επαναχρησιμοποιηθεί για την υλοποίηση μεταγλωττιστών
για διαφορετικές αρχιτεκτονικές (π.χ. gcc, portable C compiler),
- ορισμένες βελτιστοποιήσεις υλοποιούνται ευκολότερα σε ενδιάμεσο κώδικα.
Βελτιστοποίηση του ενδιάμεσου κώδικα
Η βελτιστοποίηση του κώδικα μετασχηματίζει τον κώδικα σε μια μορφή που
παράγει τα ίδια αποτελέσματα με τον αρχικά αλλά βελτιωμένα κάποια
κριτήρια απόδοσης.
Τέτοια κριτήρια μπορεί να είναι:
- η ταχύτητα εκτέλεσης του προγράμματος (συχνότερα)
- η μνήμη που καταλαμβάνει το πρόγραμμα (π.χ. όταν το πρόγραμμα
πρέπει να εκτελεστεί σε ενσωματωμένες (embeded)
συσκευές με περιορισμένη μνήμη),
- η ενέργεια που καταναλώνει το πρόγραμμα (π.χ. όταν το
πρόγραμμα θα εκτελεστεί σε φορητές συσκευές με μπαταρίες),
- η δυνατότητα εκμετάλλευσης της αρχιτεκτονικής του τελικού
επεξεργαστή (π.χ. καταχωρητών, πολλαπλών υπολογιστικών στοιχείων).
Η βελτιστοποίηση μπορεί να απαλλάξει τον προγραμματιστή από
αντιπαραγωγικές αλλαγές του κώδικα που έχουν ως στόχο να
ικανοποιήσουν τα κριτήρια αυτά και να του επιτρέψει να
συγκεντρωθεί σε άλλα ποιοτικά στοιχεία του παραγόμενου
κώδικα όπως την ορθότητα, την ασφάλεια, τη διαθεσιμότητα,
τη συντηρησιμότητα, και τη μεταφερσιμότητα.
Συχνά βελτιστοποιήσεις που γίνονται από τον προγραμματιστή
έρχονται σε αντίθεση με τα παραπάνω ποιοτικά στοιχεία.
Ορισμένες κοινές βελτιστοποιήσεις είναι οι παρακάτω:
- Απαλοιφή κοινών υποεκφράσεων
- Εκφράσεις με κοινά στοιχεία υπολογίζονται
μόνο μια φορά.
Για παράδειγμα η ακολουθία:
x = b / c;
y = 42 + b / c;
μετασχηματίζεται στην ακολουθία:
x = b / c;
y = 42 + x;
- Μετακίνηση κώδικα βρόχων (loop code motion)
-
Εκφράσεις που δεν αλλάζουν μέσα σε ένα βρόχο μετακινούνται έξω από αυτόν.
Για παράδειγμα η ακολουθία:
{
int a, b, z;
a = 8; b = 4;
for (i = 0; i < 10; i++) {
z = a / b;
printf("%d\n", z);
}
}
μετασχηματίζεται στην ακολουθία:
{
int a, b, z;
a = 8; b = 4;
z = a / b;
for (i = 0; i < 10; i++) {
printf("%d\n", z);
}
}
- Απαλοιφή άχρηστου κώδικα
-
Κώδικας που δεν εκτελείται ποτέ απαλείφεται.
Για παράδειγμα η ακολουθία:
{
int a, q;
q = 48;
return (q);
a = q / 2;
}
μετασχηματίζεται στην ακολουθία:
{
int a, q;
q = 48;
return (q);
}
- Απαλοιφή κλήσεων σε συναρτήσεις (function inlining)
-
Κλήσεις σε συναρτήσεις μετασχηματίζονται σε απευθείας χρήση του αντίστοιχου
κώδικα.
Για παράδειγμα η ακολουθία:
int
sqr(int a)
{
return (a * a);
}
main()
{
printf("%d\n", sqr(12));
}
μετασχηματίζεται στην ακολουθία:
main()
{
printf("%d\n", (12 * 12));
}
- Απαλοιφή αναδρομής από το τέλος συνάρτησης (tail recursion elimination)
-
Αναδρομή στο τέλος μιας συνάρτησης μετασχηματίζεται σε βρόχο.
Για παράδειγμα η ακολουθία:
foo()
{
printf("foo\n");
foo();
}
μετασχηματίζεται στην ακολουθία:
foo()
{
for (;;)
printf("foo\n";);
}
Παραγωγή τελικού κώδικα
Η παραγωγή τελικού κώδικα από το βελτιστοποιημένο ενδιάμεσο κώδικα
βασίζεται στην αντικατάσταση συμβολικών εντολών του επεξεργαστή
για τις συγκεκριμένες εντολές του ενδιάμεσου κώδικα.
Στο στάδιο αυτό ενδιάμεσες μεταβλητές ανατίθενται σε καταχωρητές
και μια συνάρτηση γεννάει μοναδικές ετικέτες για τις εντολές άλματος.
Συγκεκριμένες στρατηγικές περιγράφονται στις σημειώσεις της άσκησης του
μαθήματος.
Βελτιστοποίηση του τελικού κώδικα
Συχνά ο τελικός κώδικας που παράγεται μπορεί να περιέχει ακολουθίες
εντολών
οι οποίες να μπορούν να βελτιστοποιηθούν για το συγκεκριμένο επεξεργαστή.
Οι ακολουθίες αυτές μπορούν να βρεθούν εξετάζοντας ένα μικρό παράθυρο
του τελικού κώδικα, όπως αυτό θα φαίνονταν κοιτάζοντας τον
κώδικα από μια κλειδαρότρυπα.
Για το λόγο αυτό οι βελτιστοποιήσεις αυτές λέγονται και
βελτιστοποιήσεις κλειδαρότρυπας (peephole optimizations).
Για παράδειγμα η ακολουθία:
mov $12, %ax
mov %ax, %bx
mov $20, %ax
μετασχηματίζεται στην ακολουθία:
mov $12, %bx
mov $20, %ax
Επίσης η διάταξη των εντολών μπορεί να βελτιωθεί για να γίνεται
καλύτερη χρήση πολλαπλών υπολογιστικών στοιχείων που διαθέτει ο
επεξεργαστής.
Για παράδειγμα σε ορισμένους επεξεργαστές η εναλλαγή εντολών κινητής
υποδιαστολής με εντολές ακεραίων επιτρέπει στις δύο λειτουργικές
μονάδες να δουλεύουν παράλληλα.
Σύνδεση
Κατά τη σύνδεση τα ανεξάρτητα μεταγλωττισμένα τμήματα του προγράμματος
συνδέονται μεταξύ τους και με τις βιβλιοθήκες της γλώσσας για να
δημιουργηθεί το τελικό εκτελέσιμο πρόγραμμα.
Συχνά οι βιβλιοθήκες που χρησιμοποιούνται είναι κοινές ανάμεσα σε
προγράμματα και φορτώνονται δυναμικά κατά το στάδιο εκτέλεσης του
προγράμματος (Unix shared libraries, Windows DLLs).
Στην περίπτωση αυτή οι κλήσεις σε συναρτήσεις της βιβλιοθήκης
συνδέονται με ψευδοσυναρτήσεις που υλοποιούν τη λειτουργικότητα αυτή.
Κατά τη φάση της σύνδεσης γίνεται έλεγχος πως όλες οι συναρτήσεις
και μεταβλητές που χρησιμοποιούνται έχουν οριστεί και, για ορισμένες
γλώσσες όπως η C++, πως οι τύποι των συμβόλων που έχουν οριστεί σε
διαφορετικά αρχεία είναι συμβατοί μεταξύ τους.
Ορισμένες γλώσσες όπως η Java υλοποιούν μεγάλο μέρος της σύνδεσης κατά
τη φόρτωση του προγράμματος στη μνήμη για εκτέλεση.
Βιβλιογραφία
- Alfred V. Aho, Ravi Sethi,
and Jeffrey D. Ullman.
Compilers, Principles, Techniques, and Tools, pages 463–583.
Addison-Wesley, 1985.
- Diomidis Spinellis.
Type-safe linkage for variables and functions (http://kerkis.math.aegean.gr/~dspin/pubs/jrnl/1991-SIGPLAN-CType/html/tsl.html).
ACM SIGPLAN Notices, 26(8):74–79, August 1991.
- Diomidis Spinellis.
Checking C declarations at link time (http://kerkis.math.aegean.gr/~dspin/pubs/jrnl/1993-JCLT-CType/html/tsl.html).
The Journal of C Language Translation, 4(3):238–249, March
1993.
- Diomidis Spinellis.
Declarative peephole optimization using string pattern
matching.
ACM SIGPLAN Notices, 34(2):47–51, February 1999.
Εργασία του μαθήματος - H γλώσσα Aegean-C
Τελευταία νέα
- 15-12-1999
-
Νέα ενότητα: απαντήσεις σε συχνές ερωτήσεις.
- 15-12-1999
-
Νέα ενότητα: δημιουργία κώδικα για συμβολοσειρές.
- 15-12-1999
-
Νέα ενότητα: εκτέλεση και σύνδεση του μεταγλωττιστή.
- 14-12-1999
-
Καλύτερη τεκμηριώση για τη χρήση της εντολής div στις
σημειώσεις για τις αριθμητικές εντολές.
- 8-12-1999
-
Αναλυτικές οδηγίες δημιουργίας κώδικα για βρόχους, μεταβλητές, κ.λπ.
Η άσκηση
- Το μάθημα Υλικό και Λογισμικό Ι θα εξεταστεί και θα βαθμολογηθεί με την
παράδοση απαλλακτικής εργασίας.
- Οι εργασίες θα εκτελεστούν από ομάδες των τεσσάρων ατόμων.
- Κάθε ομάδα πρέπει να παραδώσει στη Γραμματεία ένα σημείωμα με τα μέλη
της ομάδας (όνομα, επώνυμο, Α.Μ.) μέχρι τη Δευτέρα 29-11-1999.
- Η ημερομηνία παράδοσης της εργασίας είναι 20-12-1999.
- Η εργασία αφορά την υλοποίηση και τεκμηρίωση του μεταγλωττιστή της
γλώσσας Aegean C σύμφωνα με τις οδηγίες που υπάρχουν στις σελίδες αυτές.
- Για την υλοποίηση μπορούν να χρησιμοποιηθούν μεταεργαλεία (yacc, lex).
- Για την υλοποίηση και την αναφορά μπορούν να χρησιμοποιηθούν οποιεσδήποτε
πηγές (σημειώσεις, Internet, βιβλιοθήκη) αρκεί να αναφερθούν.
- Όλος ο κώδικας που θα παραδοθεί πρέπει να έχει υλοποιηθεί αποκλειστικά
από τα μέλη της ομάδας.
Καταστρατήγηση του κανόνα αυτού μπορεί να οδηγήσει στο μηδενισμό μιας εργασίας.
- Η βαθμολογία της κάθε ομάδας θε εξαρτηθεί από:
- το περιεχόμενο της αναφοράς που θα παραδοθεί,
- την ποιότητα υλοποίησης του μεταγλωττιστή,
- τη συνεργασία ανάμεσα στα μέλη της ομάδας,
- την ποιότητα του πηγαίου κώδικα,
- το σχεδιασμό και τη δομή του συστήματος,
- τα πρόσθετα στοιχεία που έχουν υλοποιηθεί,
Εισαγωγή
Η γλώσσα Aegean-C είναι ένα υποσύνολο της γλώσσας C.
Δε διαθέτει πολλούς τύπους, δομές, δείκτες, αρκετούς τελεστές,
τις περισσότερες συναρτήσεις της βιβλιοθήκης
και ορισμένες εντολές.
Παρόλ' αυτά περιλαμβάνει αρκετές δυνατότητες έτσι ώστε να μπορεί
κανείς να γράψει ένα παιγνίδι όπως την προσγείωση στο φεγγάρι (Lunar
Lander).
Η παρακάτω συνοπτική περιγραφή της γλώσσας περιλαμβάνει μόνο τα στοιχεία
που πρέπει να περιλαμβάνονται υποχρεωτικά στη γλώσσα.
Η υλοποίηση της γλώσσας επιτρέπεται να προσθέσει δυνατότητες αρκεί να μην
την κάνει ασύμβατη με τη βασική γλώσσα.
Η σημασία όλων των στοιχείων της γλώσσας όπου δεν περιγράφεται διαφορετικά
είναι ίδια με αυτή της C.
Λεκτικά στοιχεία
Η λεκτική δομή της Aegean-C είναι αρκετά απλή:
- Τα σχόλια στην Aegean-C αρχίζουν με μια διπλή κάθετο (//).
- Τα ονόματα των μεταβλητών και των συναρτήσεων αποτελούνται
από πεζούς και κεφαλαίους χαρακτήρες και μπορούν μετά τον
πρώτο χαρακτήρα να περιέχουν και ψηφία.
- Οι συμβολοσειρές αρχίζουν και τελειώνουν με διπλά εισαγωγικά.
- Μέσα στη συμβολοσειρά μπορούν να περιέχονται και οι κωδικοί
διαφυγής \n και \".
- Όλα τα κενά αγνοούνται.
Μεταβλητές
- Ορίζονται μόνο καθολικές ακέραιες μεταβλητές με τη σύνταξη:
int varname;
Εντολές
Κάθε εντολή της Aegean-C τερματίζεται με ";".
Πρέπει να υποστηρίζονται οι παρακάτω εντολές:
- έκφραση ;
- while (έκφραση) { εντολές }
- if (έκφραση) { εντολές }
- if (έκφραση) { εντολές } else { εντολές }
Εκφράσεις
- Η γλώσσα Aegean-C υποστηρίζει τους παρακάτω τελεστές:
- Η αλλαγή της προτεραιότητας των τελεστών μπορεί να γίνει με τη χρήση
παρενθέσεων.
- Μια έκφραση μπορεί να περιέχει κλήσεις σε συναρτήσεις.
Συναρτήσεις χρήστη
Ο χρήστης μπορεί να ορίσει νέες συναρτήσεις με την παρακάτω σύνταξη:
όνομα_συνάρτησης()
{
εντολές
}
Η συνάρτηση με το όνομα aegean αποτελεί την είσοδο του προγράμματος.
Ορισμένες συναρτήσεις
Στη βιβλιοθήκη της Aegean-C ορίζονται οι παρακάτω συναρτήσεις:
- putstring(string)
-
Εμφανίζει τη συμβολοσειρά string στην έξοδο.
Παράδειγμα putstring("hello, world\n").
- putint(integer-expression)
-
Εμφανίζει την τιμή της έκφρασης στην έξοδο.
Για παράδειγμα putint(3+5) εμφανίζει 7.
- getint(variable)
-
Διαβάζει έναν ακέραιο από την είσοδο του προγράμματος και θέτει
την τιμή της μεταβλητής.
- getint()
-
Διαβάζει έναν ακέραιο από την είσοδο του προγράμματος και τον επιστρέφει
(εναλλακτική δυνατότητα υλοποίησης).
Παράδειγμα
Το παρακάτω παράδειγμα τυπώνει ένα ορθογώνιο τρίγωνο από αστεράκια:
// A simple program in Aegean-C
int numstars;
int i;
int j;
// Print numstars stars
stars()
{
i = 0;
while (i < numstars) {
putstring("*");
i = i + 1;
}
putstring("\n");
}
// Program entry point
aegean()
{
j = 0;
while (j < 10) {
numstars = j;
stars();
j = j + 1;
}
}
Παράδειγμα εξόδου:
*
**
***
****
*****
******
*******
********
*********
Το παράδειγμα μεταγλωττισμένο
Ο παρακάτω κώδικας είναι απλοποιημένη μορφή του κώδικα που
παράγει ο μεταγλωττιστής της C (cc -S) για το αντίστοιχο παράδειγμα σε C.
.section .rodata
.LC0:
.string "*"
.LC1:
.string "\n"
.text
.align 4
.globl stars
.type stars,@function
stars:
movl $0,i
.L2:
movl i,%eax
cmpl numstars,%eax
jl .L4
jmp .L3
.L4:
pushl $.LC0
call putstring
addl $4,%esp
incl i
jmp .L2
.L3:
pushl $.LC1
call putstring
addl $4,%esp
.L1:
ret
.globl aegean
.type aegean,@function
aegean:
movl $0,j
.L6:
cmpl $9,j
jle .L8
jmp .L7
.L8:
movl j,%eax
movl %eax,numstars
call stars
incl j
jmp .L6
.L7:
.L5:
ret
.comm numstars,4,4
.comm i,4,4
.comm j,4,4
Προσθήκες
Η γλώσσα Aegean-C μπορεί να επεκταθεί με πολλούς και διαφορετικούς
τρόπους.
Ιδιαίτερα σημαντικές θεωρούνται επεκτάσεις με δυνατότητες που δεν
υπάρχουν στη γλώσσα C.
Μερικές ιδέες για επεκτάσεις είναι οι παρακάτω:
- ορισμός τοπικών μεταβλητών
- πρόσθετες συναρτήσεις στη βιβλιοθήκη της γλώσσας
- κλήση συναρτήσεων της C
- πρόσθετοι τύποι μεταβλητών
- ορίσματα για την κλήση των συναρτήσεων
- πίνακες
- πρόσθετες δομές ελέγχου (switch, do while, break, continue, forever, goto)
- πρόσθετοι τελεστές
Αναφορά υλοποίησης
Κάθε υλοποίηση της γλώσσας Aegean-C πρέπει να συνοδεύεται από μια αναφορά
υλοποίησης. Αυτή πρέπει να περιέχει τις παρακάτω ενότητες:
- Εισαγωγή
- Περιεχόμενα
- Η ομάδα και οι ρόλοι στην ομάδα
- Περιγραφή της γλώσσας
- Σύντομη περιγραφή της γλώσσας με των προσθηκών που υλοποιήθηκαν
- Κανονικές εκφράσεις για τα λεκτικά στοιχεία
- Γραμματική της γλώσσας σε EBNF
- Λεκτική ανάλυση
- Περιγραφή του τρόπου που υλοποιήθηκε
- Προβλήματα που συναντήθηκαν και λύσεις
- Σύνδεση με τα υπόλοιπα τμήματα
- Πηγαίος κώδικας
- Συντακτική ανάλυση
- Περιγραφή του τρόπου που υλοποιήθηκε
- Προβλήματα που συναντήθηκαν και λύσεις
- Σύνδεση με τα υπόλοιπα τμήματα
- Πηγαίος κώδικας
- Πίνακας συμβόλων και συντακτικό δένδρο
- Περιγραφή του τρόπου που υλοποιήθηκε
- Δομές δεδομένων
- Προβλήματα που συναντήθηκαν και λύσεις
- Σύνδεση με τα υπόλοιπα τμήματα
- Πηγαίος κώδικας
- Παραγωγή κώδικα
- Περιγραφή του τρόπου που υλοποιήθηκε
- Προβλήματα που συναντήθηκαν και λύσεις
- Σύνδεση με τα υπόλοιπα τμήματα
- Πηγαίος κώδικας
- Παράδειγμα χρήσης
- Ένα σύνθετο, πρωτότυπο και εντυπωσιακό πρόγραμμα σε Aegean-C
- Ο τελικός του κώδικας
- Αποτελέσματα εξόδου
- Βιβλιογραφία
Πρόγραμμα εργασίας
Εβδομάδα 1
Τα παρακάτω πρέπει να έχουν ολοκληρωθεί από κάθε ομάδα:
- Παράδοση στη Γραμματεία των μελών της ομάδας
- Παράδοση στο διδάσκοντα του ονόματος της ομάδας με τα μέλη της
- Καθορισμός αρμοδιοτήτων ανάμεσα στα μέλη
- Χρονικός προγραμματισμός
- Διάγραμμα της αναφοράς (σε Word)
- Περιγραφή των στοιχείων που θα υλοποιηθούν.
Εβδομάδα 2
Τα παρακάτω πρέπει να έχουν ολοκληρωθεί από κάθε ομάδα:
- Τρόπος επικοινωνίας ανάμεσα στα τμήματα
- Αρχιτεκτονικός και αναλυτικός σχεδιασμός
- Τμήματα του κώδικα
- Τα αντίστοιχα τμήματα της αναφοράς
Εβδομάδα 3
Τα παρακάτω πρέπει να έχουν ολοκληρωθεί από κάθε ομάδα:
- Έλεγχος των τμημάτων του κώδικα
- Πρώτες προσπάθειες συνένωσης και ολοκλήρωσης
- Το παράδειγμα σε Aegean-C
- Τα αντίστοιχα τμήματα της αναφοράς
Εβδομάδα 4
- Τελικός έλεγχος και παράδοση της εργασίας.
- Κάθε ομάδα πρέπει να αφήσει σε έναν προσβάσιμο κατάλογο που θα αναφέρεται
στην αναφορά, με τακτικό τρόπο, όλα τα αρχεία που έχουν σχέση με το
μεταγλωττιστή:
- Πηγαίο κώδικα
- Εκτελέσιμο πρόγραμμα
- Παράδειγμα
- Μεταγλωττισμένο παράδειγμα
- Παράδειγμα σε εκτελέσιμη μορφή
Απλές στρατηγικές παραγωγής κώδικα
Στις ενότητες περιγράφουμε μερικές απλές στρατηγικές
για τη δημιουργία τελικού κώδικα.
Οι στρατηγικές αυτές δεν παράγουν βέλτιστο κώδικα,
αλλά είναι εύκολο να υλοποιηθούν.
Η παραγωγή κώδικα γίνεται αναδρομικά.
Ο κανόνας της συντακτικής ανάλυσης που αναγνωρίζει ολόκληρο το
πρόγραμμα μπορεί να καλεί τη συνάρτηση που παράγει τον κώδικα:
prog : dec_seq { codegen($1); }
;
dec_seq : /* ... */
Η συνάρτηση αυτή καλεί αναδρομικά άλλες συναρτήσεις ανάλογα με το είδος
του κόμβου του δένδρου.
Εκφράσεις
Η παραγωγή του τελικού κώδικα για τον υπολογισμό εκφράσεων
μπορεί να γίνει εύκολα με τη χρήση ενός μοντέλου στοίβας.
Σύμφωνα με το μοντέλο αυτό κάθε τελεστής λαμβάνει τους
τελεστέους από τη στοίβα και μεταφέρει το αποτέλεσμα πίσω
στη στοίβα.
Η διαδικασία αυτή ακολουθείται αναδρομικά για όλα τα στοιχεία
του συντακτικού δένδρου.
Στο τέλος του υπολογισμού της έκφρασης πρέπει το αποτέλεσμα
που έχει μείνει στη στοίβα να αφαιρεθεί.
Η υλοποίηση αυτή είναι κατάλληλη για αρχιτεκτονικές επεξεργαστών
που βασίζονται σε στοίβα όπως η Java Virtual Machine και
ο επεξεργαστής αριθμών κινητής υποδιαστολής της σειράς Intel Pentium,
αλλά μπορεί να χρησιμοποιηθεί και σε αρχιτεκτονικές που βασίζονται σε
καταχωρητές.
Έτσι η έκφραση b + d υλοποιείται με τη σειρά:
pushl b // Push operands
pushl d
pop %eax // Retrieve operand 1
pop %ebx // Retrieve operand 2
add %ebx, %eax // Perform operation
push %eax // Push back result
από κώδικα της μορφής:
void
codegen_add(struct s_tree *left, struct s_tree *right)
{
codegen(left);
codegen(right);
printf("\tpop %%eax\n");
printf("\tpop %%ebx\n");
printf("\tadd %%ebx, %%eax\n");
printf("\tpush %%eax\n");
}
Παράδειγμα:
a = b + c * d;
Δένδρο:
=
a +
b *
c d
Κώδικας:
pushl a
pushl b
pushl c
pushl d
pop %eax // c * d
pop %ebx
mul %ebx
push %eax
pop %eax // b + (c * d)
pop %ebx
add %ebx, %eax
push %eax
pop %esi // a = ...
pop %eax
mov %eax, (%esi)
Βρόχοι και αποφάσεις
Ο κώδικας για του βρόχους και τις αποφάσεις βασίζεται σε άλματα
σε συγκεκριμένες ετικέτες.
Τη δημιουργία του κώδικα διευκολύνει η υλοποίηση συνάρτησης
new_label που επιστρέφει νέα ονόματα ετικετών
(πιθανώς με τη χρήση των συναρτήσεων sprintf και malloc για την
αποθήκευση του αποτελέσματος).
Έτσι για παράδειγμα ο κώδικας για την εντολή while μπορεί να είναι
της μορφής:
void
codegen_while(struct s_tree *expr, struct s_tree *stmt)
{
char *loop = new_label();
char *end = new_label();
printf("%s:\n", loop);
codegen(expr);
printf("\tpop %%eax\n");
printf("\tcmp %%eax, 0\n");
printf("\tje %s\n", end);
codegen(stmt);
printf("\tjmp %s\n", loop);
printf("%s:\n", end);
}
για να παράγει κώδικα όπως τον παρακάτω:
.L0053:
pushl a
pop %eax
cmp %eax, 0
je .L0054
// code for the loop body
jmp .L0053
.L0054:
Συναρτήσεις
Ο κώδικας για την υλοποίηση μιας συνάρτησης (π.χ. με όνομα fname)
μπορεί να είναι της μορφής:
.globl fname
.type fname,@function
fname:
// procedure body
ret
Αντίστοιχα η κλήση σε μια συνάρτηση (π.χ. με όνομα fname) γίνεται
με την ακολουθία call fname.
Μεταβλητές
Για κάθε ακέραια μεταβλητή αρκεί να υπάρχει στο αρχείο της συμβολικής
γλώσσας (όχι ανάμεσα σε εντολές κώδικα) μια δήλωση της μορφής:
.comm varname,4,4
Η χρήση των μεταβλητών αυτών μπορεί να γίνει με απευθείας χρήση του
ονόματος στις αντίστοιχες εντολές:
movl %eax,varname
// ...
cmpl varname,%eax
Δημιουργία κώδικα για συμβολοσειρές
Αντίθετα με ό,τι αναφέρθηκε στο εργαστήριο, ο κώδικας για τη
δημιουργία των συμβολοσειρών δεν είναι απαραίτητο να φτιαχτεί σε
δεύτερη φάση μεταγλώττισης.
Μπορεί μια συμβολοσειρά να περιληφθεί και μέσα στις εντολές του
υπόλοιπου κώδικα αρκεί να προβλεφθεί μια εντολή jmp για να
μην εκτελείται η συμβολοσειρά ως κώδικας.
Οι ετικέτες για τη συμβολοσειρά και τον προορισμό της jmp θα δημιουργούνται
από τη συνάρτηση new_label().
Παράδειγμα για την printf:
.globl main
.type main,@function
main:
pushl %ebp
movl %esp,%ebp
jmp .LC2 // Skip the string data
.LC0: // Label for the string data
.string "hello\n" // String data
.LC2: // Label for skipping
pushl $.LC0 // Push the address of the string data ...
call printf // ... for printf to print
addl $4,%esp
.L1:
leave
ret
Στο παραπάνω παράδειγμα φαίνεται και ότι ο συμβολομεταφραστής μπορεί
να χειριστεί τους κωδικούς διαφυγής όπως το \n χωρίς επέμβαση από
το μεταγλωττιστή.
Εκτέλεση και σύνδεση του μεταγλωττιστή
Η εκτέλεση του μεταγλωττιστή της Aegean C
(ac) μπορεί να γίνει με την παρακάτω διαδικασία:
# Compile the source file lander.a to assembly file lander.s
ac <lander.a >lander.s
# Assemble lander.s; compile and link-in the Aegean runtime library (aegean.c)
cc -o lander lander.s aegean.c
Μπορεί ακόμα να αυτοματοποιηθεί με το παρακάτω Bourne shell script:
#!/bin/sh
# Names for the library and the compiler driver
LIB=aegean.c
COMP=acd
if [ "$1" = '' ]
then
echo "Usage: $0 basename (e.g. $0 lander)" 1>&2
echo "Will compile basename.a to basename via basename.s" 1>&2
exit 1
fi
$COMP <$1.a >$1.s
cc -i $1 $1.s $LIB
Απαντήσεις σε συχνές ερωτήσεις
- Χρειάζεται τελικά δεύτερη φάση δημιουργίας κώδικα για τις
μεταβλητές και τις συμβολοσειρές;
Όχι, α) ο κώδικας για τις μεταβλητές δημιουργείται εκτός των
εντολών αφού αυτές ορίζονται έξω από τις συναρτήσεις β) για
τις συμβολοσειρές υπάρχει μέθοδος δημιουργίας κώδικα που
δεν απαιτεί δεύτερο πέρασμα.
- Τι να κάνουμε με τα λάθη reduce/reduce του yacc.
Ψάξτε στο αρχείο y.output για να δείτε τους κανόνες που δημιουργούν
αυτά τα λάθη.
- Τι σημαίνει το λάθος X rules never reduced;
Κάποια τερματικά σύμβολα έχουν οριστεί σε κανόνες, αλλά δεν
έχουν χρησιμοποιηθεί σε κανέναν άλλο κανόνα.
Ψάξτε στο αρχείο y.output (στο τέλος του)
για να δείτε τα μη τερματικά σύμβολα που έχουν αυτό το πρόβλημα.
- Πως μπορούμε να βρούμε σφάλματα στο πρόγραμμά μας;
Με τον απασφαλματωτή gdb.
- Σε όλες τις μεταγλωττίσεις πρέπει να δώσετε το διακόπτη -g
(π.χ. cc -c -g gram.c ή cc -g -o comp comp.o gram.o)
- Για να τρέξετε το πρόγραμμα εκτελέστε την εντολή:
gdb name
και μετά την εντολή run.
Εντολές
- break
- καθορίζει σημεία που θέλετε να σταματήσετε.
π.χ. break main.c:22
- cont
- συνεχίζει την εκτέλεση μετά από break.
- step
- εκτελεί την επόμενη γραμμή κώδικα
- next
- εκτελεί την επόμενη γραμμή κώδικα χωρίς να μπαίνει μέσα
στις συναρτήσεις
- where
- μετά από ένα segmentation fauls σας λέει σε ποιο
σημείο έγινε.
- print expr
- τυπώνει την τιμή της έκφρασης expr
- help
- τυπώνει βοήθεια για τον gdb
- quit
- τερματίζει τη λειτουργία του gdb
Βιβλιογραφία
- Alfred V. Aho, Ravi Sethi, and
Jeffrey D. Ullman.
Compilers,
Principles, Techniques, and Tools, pages 723-751.
Addison-Wesley, 1985.
- Stephen C. Johnson.
A tour through the portable C
compiler.
In UNIX Programmer's Manual. Volume 2 --- Supplementary
Documents. Bell Telephone Laboratories, Murray Hill, NJ, USA, seventh
edition, 1979.
- Brian W. Kernighan and Rob
Pike.
The UNIX
Programming Environment.
Prentice-Hall, 1984.
- Diomidis Spinellis.
An
implementation of the Haskell language.
Master's thesis, Imperial College, London, UK, June 1990.
- Diomidis Spinellis.
Implementing Haskell: Language implementation as a tool
building exercise.
Structured Programming, 14:37-48, 1993.
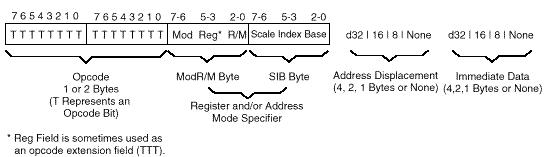
 Τελευταία αλλαγή: Τρίτη, 19 Σεπτεμβρίου 2006 6:27 μμ
Τελευταία αλλαγή: Τρίτη, 19 Σεπτεμβρίου 2006 6:27 μμ