|
http://www.dmst.aueb.gr/dds/pubs/jrnl/2003-CACM-URLcite/html/urlcite.html This is an HTML rendering of a working paper draft that led to a publication. The publication should always be cited in preference to this draft using the following reference:
|
© ACM, 2003. This is the author's version of the work. It is posted here by permission of ACM for your personal use. Not for redistribution. The definitive version was published in Communications of the ACM, 46(1):71-77, ISSN 001-0782, (January 2003). http://doi.acm.org/10.1145/602421.602422
The objective of this article is to examine, quantify, and characterize the quantity and quality of Web links used in the computing literature. Our aim is to provide concrete figures related to the availability of URL references as a function of their age, their domain, the depth of the path used, as well as the technical reasons leading to failed links.
Our research has been greatly aided by the emergence of online versions of traditional paper-based publications [4]. By tapping into the online libraries of the ACM and the IEEE Computer Society we were able to download, extract, and verify 4375 Web links appearing in print articles over the period 1995-1999. In the following paragraphs, we describe the technologies related to Web references and retrieval, outline the methodology we followed, present the obtained results, and discuss their implications.
//<user>:<password>@<host>:<port>/<url-path>
The double slash indicates that the scheme data complies with the Internet scheme syntax. In our sample, over 98% of the URLs we encountered used the HTTP URL scheme which is used to designate Internet resources accessible using HTTP (HyperText Transfer Protocol). The host is specified using the fully qualified domain name of a network host or its IP address. The default port for the HTTP scheme is 80 and is usually omitted.
For a Web page of a given URL to appear on a browser's screen a number of different technologies and protocols must work in concert. In addition, the changing realities of the Web and the Internet have vastly complicated the simple end-to-end request-reply protocol that used to form the basis of the early HTTP transactions. Any failure along the complicated chain of actions needed to retrieve a Web page will lead to a failed URL reference.
When a Web page is accessed for the first time, the name of the host must be resolved into a valid IP address. Although before the emergence of the Web there was typically a one-to-one correspondence between the IP address of non-routing hosts and a domain name the situation now is more complicated. Many hosts respond to different IP addresses, associating a different Web site with each address (virtual IP-based hosting). As IP addresses are becoming a scarce resource it is also common to associate many domain names for the same host and IP address and serve different Web sites based on the host name used for a given page request (virtual name-based hosting). Finally, Web sites receiving a lot of traffic may associate different IP addresses and hosts for the same domain name in order to distribute traffic among hosts.
The path appearing in a URL will nowadays not necessarily match with a corresponding local file on the server. Web servers provide a number of mechanisms for managing namespaces. Some of them are: the creation of a separate namespace for every local user, the definition of protection domains and access mechanisms, the support of aliases to map namespaces to local directories, and the dynamic creation of content using technologies such the common gateway interface (CGI) and active server pages (ASP). In addition, a feature of the HTTP protocol called content negotiation allows a server to provide different pages based on technical or cultural characteristics of the incoming request (e.g. bandwidth, display technology, languages the user can understand).
One final complication results from the fact that Web transactions seldom now follow the idealized IP path from the user host to the server. Both ends are likely to be protected by firewalls actively blocking or even modifying content that passes through them. At the user-end routers utilizing network address translation (NAT) mechanisms as a way to manage a limited pool of IP addresses are likely to hide the IP address of the end-host from the server. Finally, proxy servers-working either in cooperation with the end-user or transparently intercepting requests-will cache documents and serve them without communicating with the original server.
Any failure along the complex path we described will often result in a failed request for a URL. The HTTP protocol defines 24 different errors that can occur within an HTTP exchange. In addition, some errors can occur before the client and server get a chance to communicate. In practice, while verifying thousands of URLs we encountered the following errors:
Although a large number of document collections are available on the Web, we decided early-on to limit our research to two publications: IEEE Computer (Computer), and the Communications of the ACM (CACM). Our decision was based on the fact that both publications:
However, by concentrating our research on two publications we limited the generality of the obtained results. CACM and Computer do not represent the typical journal as, contrary to common practice, editors verify the URLs before publishing a paper thus filtering-out invalid URLs submitted by the authors or invalidated during the period leading to the publication. In addition, publications from other scientific domains, or with a different focus such as archival research journals, or general circulation magazines are likely to exhibit different characteristics regarding the appearance of URLs and their validity. To allow other researchers build upon our work, we have made available the complete set of URLs, their source, and the programs used to verify their accessibility at the article's companion web site http://www.spinellis.gr/sw/url-decay.
We first downloaded all articles appearing in the two publications using a set of programs that crawled through the digital libraries of the two organizations. This phase started on February 21st, 2000 and was completed on May 5th, 2000. Over 9GB of raw material were downloaded during the process.
CACM articles are available on the ACM digital library in PDF format. In order to extract URLs we first converted the articles into text form. CACM articles appearing in the library before 1995 are scanned images; we did not attempt to OCR those issues. As 1995 was also the earliest year in which Computer was available on-line we decided to use the articles in the period 1995-1999. In total we used 2471 items: 1411 articles from Computer (38.2MB of HTML) and 1060 articles from CACM (18.9MB of text).
We extracted URLs from the full text body of each article. The IEEE Computer Society digital library provides articles in both HTML and PDF format. Articles that appear in HTML format have embedded URLs tagged as hypertext references (HREF), which can be easily extracted. The extraction of URLs from the text of the CACM articles proved more challenging; it was performed using a custom filter program and manual inspection.
After extracting the URLs we removed duplicate appearances of URLs in the same article (21 cases for CACM, 362 for Computer). In total we ended up with 4224 URLs: 1391 (33%) obtained from CACM and 2833 (67%) obtained from Computer. We found a mean number of 1.71 URL references per article (median 0, mode 0) with a maximum of 127 URL references in a single article. A single complete URL was referenced by a mean number of 1.49 (median 1, mode 1) different articles in our sample with a maximum of 22 references for a single URL. The HTTP scheme was by far the most widely used: 4158 URLs (98%) used the HTTP scheme and only 66 URLs (2%) used the FTP scheme.
Finally, we verified the accessibility of each URL by attempting to download each identified resource. We repeated this procedure three times, with a weekly interval between different runs, starting at different times, from two different networks and hosts to investigate transient availability problems. No substantial differences were found between the runs. Here we report the results obtained on June 29th and 30th 2000. We did not merge positive results from different runs; our results reflect a model where a reader tries to access a URL one single time. We did not perform any semantic processing on the retrieved URLs; we assume that if a URL could be accessed its contents would match the intent of the original reference.
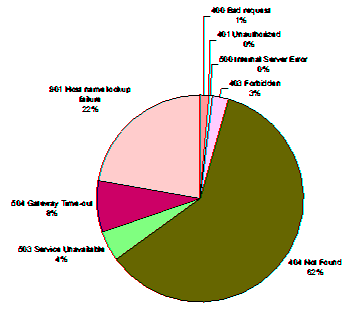
Despite our original reservations concerning the source material we used, the results we obtained have been corroborated by similar studies of web-published documents [9]. Of the URLs we checked 72% could be retrieved without a problem. The successful retrieval rates differ depending on the URL source: 63% for CACM and 77% for Computer URLs. This difference can probably be attributed to the fact that Computer URLs are tagged as such in the HTML article text. The reasons for failed URL retrievals are classified in Figure 1. By far the most common reason was that the resource referenced no longer existed on the given server (error 404, 60% of the failures). The second most common (22%) failure reason was an invalid host name (error 901), while network problems (error 504) only represented a 8% of the failures; a tribute to network availability. It is interesting to note that 83% of the failures can be attributed to invalid URL hostnames or paths (errors 901 and 404) i.e. that addressing in all its forms is the predominant factor in URL failures. The clustering of failure modes allows us from this point onwards to classify failed URLs into just two different groups: the network problems that occur while trying to reach the host (errors 504 and the DNS access subset of the 901 errors) and the server problems that occur while resolving the host name and once the host is reached.
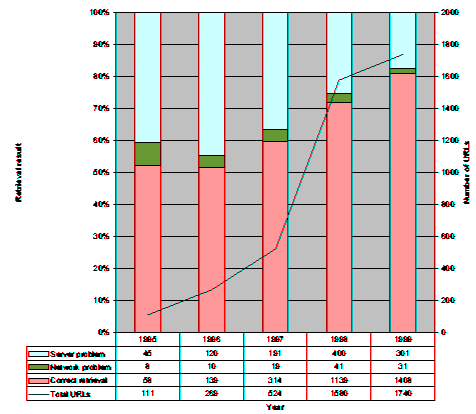
The temporal aspect of URL references and respective failures is extremely interesting. As can be seen in Figure 2, URL references exhibited an exponential increase from 1995 to 1998 and appear to be leveling-off afterwards. This plateau is to be expected since the number of references in articles are constant over time (editors in the examined journals often impose limits); URL references apparently increased by displacing citations to printed sources. The most striking result that can be deduced from Figure 2 is that in our sample
the half-life of a referenced URL is approximately 4 years from its publication date
i.e. that four years after their publication about 50% of the URLs are not accessible. It is also interesting to note that 20% of the URLs are not accessible one year after their publication and that after that the first year the URL decay is constant at about 10% per year for the next three years. Although URL decay appears to stabilize after that point, (a result that appeals to intuition-these will be URLs to authoritative sources on properly maintained servers) we have not sufficient historical data to substantiate this claim. The 20% decay during the first year can either be attributed to a high infant URL mortality or the large period an article takes from its inception to its publication.
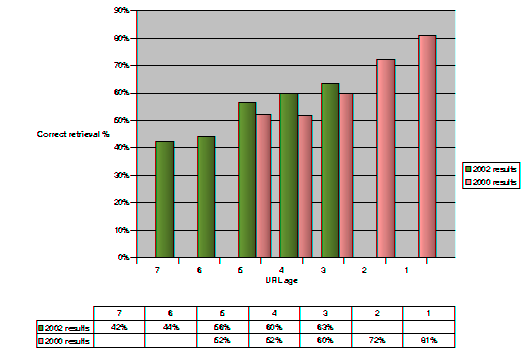
We were able to repeat the URL accessibility test two years after the 2000 exercise, on August 2002. The combined results of the two tests appear in Figure 3. What is apparent is the inexorable decline of the accessibility of the 1998 4-year old URL references towards the 60% mark (as opposed to the 50% we originally predicted), the further decline of the 1995 and 1996 URL accessibility towards 40%, and a small but significant difference between the aging behaviour of older and newer URLs. For the years for which we have comparable data (URL ages 3 to 5 years) more recent URLs (coming from the years 1997-1999 in the 2002 test) appear to be more accessible than their predecessors (years 1995-1997 in the 2000 test). This difference in URL aging over time can probably be attributed to increased author efforts to cite URLs that are less likely to disappear, and improved web site maintenance practices.
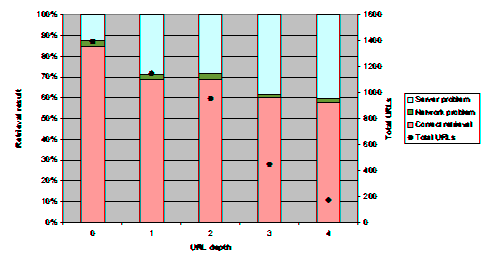
One result that appears to have both predictive and prescriptive value concerns the relationship between the path depth of a given URL and its failure rate. As can be seen in Figure 4, the number of URLs of a given path depth is linearly decreasing between path depths 0 and 2; it appears to decrease at a exponential rate after that point. What is significant is that while the network-related problems are, as expected, approximately constant relative to the path depth, server-related problems (mainly 404 errors) increase as the depth increases. While no direct causation can be deduced, we can point out that
deep path hierarchies are linked to increased URL failures.
This result is not immediately intuitive. A deep hierarchy is a sign that someone spent effort to organize content in a structure that should persist over time. We have two explanations for this result:
We also examined the relationship between two other URL properties-references to specific files and user directories-and the respective failure rates. We identified URLs that referenced specific files (e.g. http://www.acm.org/pubs.html) rather than directories (e.g. http://www.acm.org/cacm) assuming that if the last part of the URL contained a dot it referred to a file. The difference between the two URL classes is noteworthy: in total 40% of URLs referring to files could not be retrieved whereas only 23% of URLs referring to directories had the same problem.
Some HTTP servers allow the specification of separate content directories maintained by end-users using the ~username convention. We hypothesized that URLs to such user directories (which we found to be 13% of the total) were more likely to fail than others due to the higher mobility of individuals. In fact only 24% of these URLs had retrieval problems; the respective figure for the rest was 28%.
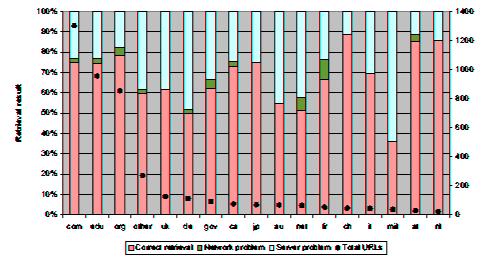
In Figure 5 we list the retrieval result of the referenced URLs according to their top-level domain. The domains .com, .edu and .org represent 74% of all referenced URLs. Other studies [7] have estimated that on a global scale only 6% of the Web servers have scientific or educational content. Since in our sample URLs in the .edu domain form 23% of the total we can deduce that these URLs are referenced three times more frequently than what would be expected by their population. It is interesting to note that URLs in the .com and .edu domains are equally likely to fail; a startling result given the radically different management models prevalent in educational establishments and companies. Also remarkable is the fact that URLs in the .org domain are less likely to fail than the other two categories; contrary to intuition, it appears that the management structures used by the ad-hoc volunteer efforts typically hosted in .org domains result in more stable Web sites.
The emergence of publications that appear both electronically and on paper [6] can help alleviate the tensions between the two formats. It has certainly helped us trace URL references, and we can envisage a system that would keep hypertext references up-to-date in the non-paper part of hybrid publications. In the future, citation linking [5], provided as a service by publishers or public-service efforts [8], may lead to publication formats that actively support hypertext links across time.
Uniform Resource Names (URNs) have been proposed as a way to provide persistent, location-independent, resource identifiers [11]. However, URNs-typically consisting of an authority identifier followed by a string-are at a low level similar to URLs. Organizations that find it difficult to organize URLs will face the same problem with URNs and vice versa [2]. While URNs can solve the problem of maintaining connection with a moving target, they can not solve the problem of accessing deleted material.
A technology specifically targeting the persistent and interoperable identification and exchange of intellectual property in the digital environment is the Digital Object Identifier (DOI) system [12]. A DOI, consisting of a publisher prefix and a suffix identifying the work, is registered together with the corresponding URL and metadata in a central DOI directory working as a routing system. DOI-based requests are forwarded to the directory and are resolved to a current and valid URL supplied by the respective rights holder. Based on this technology, a large number of publishers (including the ACM and the IEEE) accounting for over 3,500 journals have teamed-up to provide CrossRef, a reference linking service.
One alternative way for reestablishing contact with invalid URL references is to use one of the Web's main search engines. However, research indicates that search engine coverage is low (around 16%) and decreasing, indexing varies considerably between different sites (with educational and non-US sites more likely to be disadvantaged), while the use of metadata which could be used to automatically locate citations is quite low [7]. The same research estimates the amount of data in the publicly indexable Web to 15 Tbytes; we therefore believe that the creation of historical ``snapshots'' of the Web is not within the realm of our current technical capabilities.
Based on our results, ways to alleviate the specific problem of invalid URL references appearing in print articles can be identified by concentrating on the distinct roles of the principal stakeholders involved in the process.
Professional societies, and publishers should draft and encourage the use of sound Web citation practices and verify referenced URLs as part of an article editing process. Both should also work towards establishing online repositories for Web material (such as the ACM Computing Research Repository) and endow those with policies to guarantee their longevity in the very long term. Publishers of archival research journals have an additional obligation towards the future generations that will access their material. Although some URLs are less important than others, a guideline limiting Web citations in archival journals to organized collections with concrete long-term retention policies may be the only responsible action consistent with the current state of the art.
Researchers should appreciate the limitations of Web citations regarding their probable lifespan and use them sparingly rather than gratuitously keeping in mind that the Web is not an organized library. Where possible, they should prefer citing the published version of a work to its online version, and citing material in organized collections over material in corporate or personal Web pages. In some cases they could even exert peer pressure to authors of material the would like to reference encouraging them to move it to an organised online repository. In addition, researchers should reference items using the shortest possible path, and avoid references to ephemeral data (e.g. non-archived news reports) and proprietary material.
Finally, maintainers of Web sites should try to preserve the validity of existing URLs and clearly indicate ephemeral pages that should not be cited (or linked). The standardization of appropriate HTML meta tags for indicating the projected longevity of a particular page will help all the above stakeholders unambiguously identify the extent to which a page can be cited.
A more ambitious scheme would have all stakeholders cooperate to establish a long term archive of referenced material, similar in nature with existing Internet archival efforst such as www.archive.org. Citations would reference the archived version of Web material:
http://archive.acm.org/http/2000.03.02.23.45.12/www.ibm.com/ai.htm
Under such a scheme libraries and professional societies would establish and promote the use of archival services perpetually keeping copies of referenced material-subject to intellectual property restrictions. Researchers would cooperate with Web-site producers to obtain copies of their material for archival while Web-site producers should be encouraged to draft and implement liberal policies for placing cited material under long-term archival custody.
The Web has revolutionized on a global scale the way we distribute, disseminate and access information and, as a consequence, is creating a disruptive paradigm shift in the way human scientific knowledge builds upon and references existing work. In the past, libraries could provide reliable archival services for books and printed journals; the emergence of the Web is marginalizing their role. In the short term none of the approaches towards solving the general problem of dangling URL references is likely to be a panacea. It is therefore important to appreciate the importance of Web citations and invest in research, technical infrastructures, and social processes that will lead towards a new stable scientific publication paradigm.