
|
http://www.dmst.aueb.gr/dds/pubs/jrnl/2003-TSE-Refactor/html/Spi03r.html This is an HTML rendering of a working paper draft that led to a publication. The publication should always be cited in preference to this draft using the following reference:
|
The source code analysis problems introduced by the C preprocessor can be overcome by considering the scope of preprocessor identifiers during a program's language proper semantic analysis phase. Having performed this analysis, refactoring transformations can be performed by tagging all identifiers with their original source code position, and taking into account the identifier equivalence classes formed by the combined preprocessor and language proper scopes.
In the following sections we describe the problems introduced by preprocessing and introduce algorithms for precisely mapping a C/C++ program's semantic information to its non-preprocessed source code. Furthermore, we demonstrate the application of our methods in the CScout toolchest (http://www.spinellis.gr/cscout) that programmers can use to perform rename and remove refactorings.
Macro substitutions are often trivial, used to define constants (Figure 1-1), inline-compiled functions (Figure 1-2), or implement call-by-name semantics (Figure 1-3). However, macro substitutions are also often used to create generic functions overcoming limitations of the language's type system (Figure 1-4), affect the language's reserved words in, often misguided, attempts to enhance readability (Figure 1-5), create shortcuts for initializing structures (Figure 2), and dynamically generate new code sequences, such as function definitions, by pasting together tokens, or substituting operators and whole code blocks (Figure 3) [15]. File inclusion is typically used to bring into the scope of a given compilation unit declarations of elements defined in other units (and declared in separate header files), thereby providing a way to communicate declarations and type information across separately-compiled compilation units.
As a result of the changes introduced by the preprocessing phase the parsing of the language proper, and therefore any meaning-preserving transformation, can not be performed unless the code is preprocessed. However, after the preprocessing step has been performed, the parse tree-based transformation approach we outlined can not be used, because the tree contains the code in the form it has after its preprocessing. This code differs significantly from the original code, and in that representation it is neither portable (since standard included files typically differ between compilers, architectures, and operating systems), nor readable or maintainable by people. In addition, file inclusion introduces complex dependencies between files, propagating bindings between declared, defined, and used identifiers upwards and downwards in the file inclusion tree.
As an illustrative example of the complications introduced by preprocessing, the code body of a simple loop written in C to copy characters from the program's standard input to its output expands from 48 to 214 characters, while the inclusion of the Microsoft Windows SDK windows.h header file results in a preprocessed source code body of 158161 lines, with identifiers spanning as many as 39 different files. Consequently, and to the best of our knowledge, there are no known general purpose approaches for automatically performing non-trivial source-to-source transformations on C and C++ code in a way that preserves the original code structure. This is a significant problem, because these languages are popular, huge collections of code are written in them, and many important maintenance-related activities such as refactoring could be automated and performed in a safe and cost-effective manner. Ernst et al. [16] provide a complete empirical analysis of the C preprocessor use, a categorization of macro bodies, and a description of common erroneous macros found in existing programs. Furthermore, recent work on object-oriented design refactoring [5] asserts that it is generally not possible to handle all problems introduced by preprocessing in large software applications.
extern int v_left, v_right, v_top, v_bottom;
#define sv(x) {#x, &v_ ## x}
struct symtab {
char *name;
int *val;
} symbols[] = {
sv(left),
sv(right),
sv(top),
sv(bottom),
};
Code after preprocessing:
extern int v_left, v_right, v_top, v_bottom;
struct symtab {
char *name;
int *val;
} symbols[] = {
{"left", &v_left},
{"right", &v_right},
{"top", &v_top},
{"bottom", &v_bottom},
};
#define defblit(name, op) \
blit_ ## name(char *s, char *d, int c) \
{ \
for (int i = 0; i < c; i++) \
d[i] = s[i] op d[i]; \
}
defblit(xor, ^)
defblit(and, &)
defblit(or, |)
Code after preprocessing:
blit_xor(char *s, char *d, int c) { for (int i = 0; i < c; i++)\
d[i] = s[i] ^ d[i]; }
blit_and(char *s, char *d, int c) { for (int i = 0; i < c; i++)\
d[i] = s[i] & d[i]; }
blit_or(char *s, char *d, int c) { for (int i = 0; i < c; i++)\
d[i] = s[i] | d[i]; }
We can classify the techniques typically used based on the level of code integration they apply to.
Programmers typically deal with individual source files. Most current source transformation tools for C/C++ operate at a lexical level on single files. Code beautifiers such as the Unix-based cb and indent tools can improve the readability of programs by rearranging whitespace. As the definition of whitespace is the same for both the C preprocessor and the C/C++ language proper, the conservative transformations these tools employ can in most cases be safely applied. The tools reformat the program based on a naive parsing of the code that takes hints from delimiters such as braces and brackets; their operation can be fooled by the use of certain macro substitutions, but, since the tools only rearrange whitespace, the program will only be suboptimally formatted yet still perform its intended operation. Source code editors work following imperative, task-oriented text-processing commands. Some editors can automatically indent code blocks, or display reserved words and comments using special colors; the approaches employed depend on heuristics similar to those used by the code beautifiers.
A source file together with the files it includes forms a compilation unit. A number of code analysis and code generation tasks are performed on this entity. Compilers typically perform (after the preprocessing phase) syntactic and semantic analysis and code generation. In addition, tools such as lint [17] and its descendants preprocess the file (sometimes using custom-developed include files) and employ heuristics to detect common programmer errors. The PCp3 preprocessor-aware C source code analysis tool [18] tightly integrates a customized preprocessor with a C language parser to allow code written in Perl to accurately analyze the use of preprocessor features. The object file resulting from the compilation can also be analyzed to accurately determine, at least, all globally visible symbols defined and referenced in a given compilation unit (subject to name-mangling restrictions, see below).
Multiple compilation units are linked together into a linkage unit which in most cases comprises an executable program. The linkers typically lack information about the syntax and semantics of the language; as a result techniques such as name mangling [19] are often used to perform some kind of primitive type checking at link time [20]. A number of integrated development environments and tools such as cscope and ID utils allow the user to specify the files comprising a linkage unit and thereby perform textual searches or replacements across all files. In addition, profilers [21] and debuggers [22] can be used to analyze the program's operations; however, they fail to deal with source elements that were replaced during the preprocessing step.
Finally, a workspace or program family [5] consists of a collection of source code files that form multiple linkage units. The collection, typically organised through common shared header files and separately compiled library files, contains many interdependencies between files belonging to different compilation units through the sharing of source code via source file inclusion (during preprocessing) and linking. Typical examples of workspaces are operating system distributions where both the kernel and hundreds of user programs depend on the same include files and libraries as well as software product lines [23,24]. Again, only textual processing can be performed at this level, either using an IDE, or the text and file processing tools available in environments such as Unix [25]. As an example, locating the string printf in the source code of an entire operating system source code base can be performed using the command find -name '*.[ch]' -print | xargs grep printf.
In all the cases we outlined above, an automated textual operation, such as a global search and replace, will indiscriminately change identifiers across macros, functions, and strings. Code analysis tasks, such as the location of all files where a particular identifier is used, are equally haphazard operations. This state of affairs makes programmers extremely reluctant to perform large scale changes across extensive bodies of C/C++ code. This observation is anecdotally supported by the persistence of identifier names (such as creat and splx in the Unix kernel) decades after the reasons for their original names have become irrelevant. The readability of existing code slowly decays as layers of deprecated historical practice accumulate [26] and even more macro definitions are used to provide compatibility bridges with modern code. Two theoretical approaches proposed for dealing with the problems of the C preprocessor involve the use of mathematical concept analysis for dealing with cases where the preprocessor is used for configuration management [27], and the definition of an abstract language for capturing the abstractions for the C preprocessor in a way that allows formal analysis [28].
In the following sections we describe a method for precisely identifying and analyzing the use of identifiers in the original, non-preprocessed body of source code, taking into account the syntax and semantics of the C or C++ programming language. Tools using the precise classification of identifiers can then be used to perform renaming and remove refactorings, map dependencies between source files, identify the impact of architectural changes, optimize the build process, and generate high-quality metrics. Being able to globally rename an identifier name in an efficient manner can help programmers refactor and maintain their code by having identifier names correctly reflect their current use and the project's contemporary naming conventions. The practice is also important when code is reused by incorporating one body of code within a different one; in situations where the reused code will not be maintained in its original context the naming of all identifiers of the grafted code should change to conform to the style used in the workspace into which it was added. Finally, the replacement of identifiers with mechanically generated names can be used as a method to obfuscate programs so that they can be distributed without exposing too many details of their operation [29].
Modern language designs have tried to avoid the complications of the C/C++ preprocessor. Many features of the C++ language such as inline functions, and const declarations supplant some common preprocessor uses. Java does not specify a preprocessing step, while C# [30] specifies a distinct scope for the defined preprocessor identifiers that is visible only within the context of other preprocessor directives. However, the preprocessing technology is still relevant in an number of contexts. Preprocessing is often used as a source-to-source transformation mechanism to extend existing languages [31]. In addition, the preprocessor is also used, in all the C++ implementations we are aware of, to implement the language's standard library, and, in particular, to support-via the file inclusion mechanism-the generic programming facilities of templates and the standard template library (STL) [32].
A set of source code files S for a statically-scoped first order language is processed before compilation by a general purpose macro processor supporting file inclusion, macro substitution, and token concatenation. A single instance of an (identifier) token t in one of the files Si is modified resulting in a new token t�. Propagate this change creating a new, syntactically and semantically equivalent, set of files R differing from S only in the relevant names of identifier tokens.
With the term ``first order language'' we restrict our language (or our approach's domain) to systems that do not have (or utilize) meta-execution or reflection capabilities. Systems outside our domain's scope include meta-interpreters implemented in non-pure Prolog, Scheme meta-evaluators [33], runtime calls to the interpreter in Perl and Tcl/Tk, and the reflection [34] capabilities of Java [35] and C# [30]. In addition, the problem definition assumes that t and t� do not directly or indirectly (after preprocessing) have a special meaning in the language the programs are written in that will result in R never being semantically equivalent to S. As an example, it would in most cases not be legal to modify an existing printf identifier in a C program (printf is part of the standard library for hosted implementations), or to rename an identifier into class in a C++ program (class is a C++ reserved word). This clarification is needed, because tokens treated as identifiers in the preprocessing stage can have a special meaning (reserved word, or name of a library facility) in the target language. Finally, we assume that t� does not clash in any legal context with existing identifiers in a way that would change the semantic meaning of R. The analysis tasks we identified in the previous sections can be trivially performed by locating the identifiers that would require modification without actually changing them.
Informally, we want to automate the process followed by a programmer renaming or locating all instances of an entity's name. We will describe the approach in four steps of gradually increasing refinement. Central to our approach is the notion of token equivalence. Given the token to be modified t we want to locate the set of tokens Et occurring in S so that by changing each ti: ti ∈ Et into t′ we will obtain R. We define the set of tokens Et as the equivalence class of t. For a complete workspace we maintain a global set V containing all equivalence classes V : ∀i Ei ∈ V
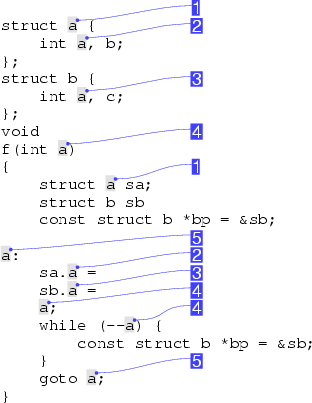
As an example, consider the (contrived) example of the C++ program in Figure 4. The equivalence classes for the identifier a are marked in the right margin. The identifier a is used in five distinct namespaces defined in C++: it is the name of a structure tag (1), a member of two different structures (2, 3) (the members of each structure reside in their own namespace), a formal argument to the function f (4), and a label in the function body (5). Significantly, the two instances of the pointer variable bp are not semantically equivalent under our definition, because, although they both point to the same underlying object (sb), they are different according to the scoping rules of the C++ language.
Determining the semantic equivalence classes of identifiers is relatively straightforward and performed routinely by all compilers: one follows the scope rules of the language specification [36]-taking into account type inference rules for matching the declarations and corresponding uses of structure and union members.

The lexical equivalence of tokens forms the basis of our method by taking into account the scope and semantics of preprocessing commands. A lexical equivalence class may contain identifiers appearing on the right hand side of macro definitions and identifiers in the code body. Consider the C code in Figure 5. The two instances of b marked (1) form a lexical equivalence class: both must be changed to the same new value in a transformation that preserves the operation of the original program. Notice how the name of the label b is not part of the equivalence class; modifying it independently will not affect the rest of the program.
The operation of the preprocessor can also create equivalence classes between identifiers that would not be semantically equivalent under a language's rules. The macro val in Figure 5 defines an accessor function; a common occurrence in C programs. Note that the macro is used in a polymorphic fashion: it is applied to two variables containing pointers to a different structure type. This macro definition and application brings the semantically distinct v fields of the structures a and b under the same lexical equivalence class. All three instances of v must be changed to the same new name in a meaning-preserving source transformation. Note that the two structure declarations, the definition of the the val macro, and its application could occur in four different files (that may even belong to different linkage units) combined using the preprocessor's file inclusion commands.
Lexical equivalence can also be introduced by the macro processor without macro definition, through the inclusion of the same file in multiple compilation units (a common method for importing library declarations). If the included file declares elements with static (compilation unit) scope, then identifiers in two different compilation units may be lexically equivalent, even though they are defined in isolated scopes, as a change in one of the files, must be propagated through the common included file to the other. A representative example also appears in Figure 5. The identifiers uint and s are shared between the two C files only because they both include the same header file.
Tokens can be grouped into equivalence classes using the following algorithm.
Perform macro substitutions; the resulting code shall consist of references to the original tokens.
Parse the program.
Having grouped tokens into equivalence classes, source code modifications can be performed by locating the equivalence class Er to which a particular token tr belongs and correspondingly modifying all tokens in that class in the source code position they were found.

We introduce the notion of partial lexical equivalence to deal with the issue of token concatenation. The preprocessor used in the ANSI C and C++ languages can concatenate tokens to form new ones using the ## operator. In addition, historical practice in pre-ANSI versions of the preprocessor also allowed token concatenation by separating them by a comment in a macro replacement pattern. The result of this capability is that there is no one-to-one equivalence between tokens in the original source code and the tokens on which the semantic analysis is performed. Parts of an identifier can belong to different equivalence classes, as shown in Figure 6 by the identifiers marked 1 and 2.
The procedure we described in the previous section can be amended to deal with this case by handling subtokens. Each token ti now consists of a concatenation (denoted by the ⊕ symbol) of ni subtokens sij:
| (1) |
| (2) |
| (3) |
| (4) |
| (5) |
Under the preprocessor regime, macro names are semantically equivalent with the tokens they replace. When a macro name token ta: ta ∈ Ea replaces a token tb: tb ∈ Eb in the program body, the equivalence classes Ea and Eb are to be merged following the process described in step 4 in Section 3.2. In addition, multiple definitions of the same macro with the same arguments and replacement should unify both the macro name and its arguments and the corresponding replacement lists, since they form legal multiple definitions of the same macro [12].
The formal arguments of preprocessor macros are only meaningful within the context of the actual macro definition. Therefore, each occurrence of a formal macro argument ta: ta ∈ Ea found as a token tb: tb ∈ Eb in the macro body, shall result in the equivalence classes Ea and Eb being merged following again the process described in step 4 in Section 3.2.
An example of the issues described above is depicted in Figure 6. Note that the merged equivalence class (3) of the macro PI will not be determined until the expansion of the macro TWOPI as part of the area initialization as under the ANSI C standard after a macro substitution the replacement token sequence is repeatedly rescanned for more defined identifiers [12].
#ifndef HEADER_INCLUDED /* Header code */ #define HEADER_INCLUDED #endif /* HEADER_INCLUDED */
will not unify the (originally undefined) macro HEADER_INCLUDED with its subsequent definition. Similarly, multiple tests against the same undefined macro name, often used to conditionally compile non-portable code, will fail to unify with each other. The first problem can be solved by including all headers at least twice; hardly an ideal proposition. Both problems can also be solved by employing heuristic techniques or manually defining the macros before the corresponding test. None of the solutions is completely error-proof: a heuristic unifying undefined macros with a subsequent definition may fail in cases where the two are not related; the manual definition of a macro may cause the program to be processed in ways that are not appropriate for a given compilation environment.
The refactoring browser provides a Web-based interface to a system's source code and its identifiers for examining the source and aiding the realization of rename (e.g. ``rename-variable'' [39]) and remove (e.g. ``Remove Parameter'' [4]) refactorings. Using the swill embedded Web server library [40] the analyzed source code collection can be browsed by connecting a Web client to the tool's HTTP-server interface. Each identifier is linked to a Web page containing details of the equivalence class it belongs to. A set of hyperlinks allows users to
Examine the source code of individual files, with hyperlinks allowing the navigation from each identifier to its equivalence class page.
View the semantic information associated with the identifiers of each equivalence class. Users can find out whether the equivalence class is read-only (i.e. at least one of its identifiers resides in a read-only file), and whether its identifiers are used as macros, macro arguments, structure, union, or enumeration tags, structure or union members, labels, typedefs, or as ordinary identifiers. In addition, users can see if the identifier's scope is limited to a single file, if it is unused (i.e. appears exactly once in the file set), the files it appears in, and the projects (linkage units) that use it. Unused identifiers point to functions, macros, variables, type names, structure, union, or enumeration members or tags, labels, or formal function parameters that can be safely removed from the program.
Substitute a given equivalence class's identifier with a new user-specified name.
Write back the changed identifiers into the respective source code files. A single pass through each processed source file will identify file offsets that mark the starting point of an equivalence class associated with a changed identifier name and substitute the number of characters that comprised the old identifier name with the new name. Thus the only changes visible in the program will be the modified identifier names.
The above functionality can be used to semi automatically perform rename and identify candidates for remove refactorings. Name clashes occurring in a rename refactoring are not detected since this feature would require reprocessing the entire source code base-a time consuming process. Remove refactorings can be trivially performed by hand, after identifiers that occur exactly once have been automatically and accurately identified.
The obfuscate back-end systematically renames the identifiers belonging to each equivalence class, thus creating a program representation that hinders reverse-engineering attempts. This source (with appropriate selection of the specified read-only files) will remain portable across architectures, and can be used as an architecture-neutral distribution format such as the one proposed by Hansen and Toft [41]. Since the source is distributed in its non-preprocessed form, portability problems stemming from different contents of included files across systems are obviated. Furthermore, adding to the set of read-only files the system's source files where configuration information is specified (e.g. config.h) will result in a source code base where the configuration commands and macros are still readable and can be tailored to a given platform.
Finally, the SQL back end provides additional analysis and processing flexibility through the use of SQL commands. The SQL back end creates an ANSI SQL-92 script that contains all equivalence class properties and represents all links between equivalence classes, tokens, files, and projects. The scripts have been tested with Postgres and the embeddable, Java-based hsqldb databases. All program text that is not part of identifiers is stored in a separate database table allowing the complete source file base to be reconstituted from a (potentially modified) database.
The build engine functionality is required so that CScout will process multiple compilation and link units as a single batch. Only thus can CScout detect dependencies across different files and projects. Each compilation unit can reside in a different directory and can require processing using different macro definitions or a different include file path. In a normal build process these options are typically specified in a Makefile [42]. The CScout operation is similarly guided by a declarative workspace definition file.
The C preprocessor part converts the source code input into C preprocessor tokens. It tags each token with the file and offset where it occurs, and creates a separate equivalence class for each token. Operating system-specific system calls are used to ensure that files included by various compilation units using different names (e.g. through distinct directory paths or by following hard and symbolic links) are internally identified as the same source file. The preprocessor part performs the normal C preprocessor functions we described in Section 2.1. When defining and replacing macros and when evaluating preprocessor expressions CScout will merge equivalence classes as described in Section 3.4.
The semantic analysis part reclassifies the preprocessed tokens according to the (slightly different) token definition of the C language proper and follows the language's scoping and namespace rules to determine when two identifiers are semantically equivalent in the sense we described in Section 3.1. During this phase each object identifier token is tagged with enough type information to allow the correct classification of structure and union member names appearing on the right of the respective access operators. A vector of symbol table stacks is used to implement the language's scopes and namespaces. Each time a symbol table lookup determines that the token currently being processed is semantically equivalent with a token already stored in the symbol table the corresponding equivalence classes are merged together.
The equivalence class merge operations we described in the previous two paragraphs are always performed taking into account the partial lexical equivalence rules we described in Section 3.3. If one of the two unified tokens consists of subtokens, the corresponding equivalence classes are split, if required, and then appropriately merged.
At the end of the semantic analysis phase every token processed can be uniquely identified by its file and offset tuple t(f, o) and is associated with a single equivalence class: t ∈ Et. This data structure can be saved into a relational database for further processing. Equivalence classes containing only a single C identifier denote unused identifiers that the CScout user should probably delete. The first step for renaming an identifier involves associating a new name with the identifier's equivalence class. After all rename operations have been specified and the changes to the source code are to be committed, each source file is reprocessed. When the read offset o′ of a file f′ being read matches an existing token t′(f′,o′) its equivalence class Et′ is examined. If the equivalence class has a new identifier n associated with it, CScout will read and discard len(t′) characters from the file and write n in their place. Creating a version of a file with identifier hyperlinks involves similar processing with the difference that all identifier tokens are tagged with a hyperlink to their equivalence class. Finally, obfuscating the source code involves associating a new random unique identifier replacement with each equivalence class.
Quantifying the performance of CScout we note that the time required to process an application is about 1.5 times that required to compile it using the GNU C compiler with the default optimization level. The memory resources required are considerable and average about 560-620 bytes per source line processed. We have successfully used CScout to process medium sized projects, such as the apache Web server and the FreeBSD kernel, and have calculated that the analysis of multi million source code collections (such as an entire operating system distribution) is not beyond the processing capability of a modern high-end server. Specifically, we estimate that our current implementation could process the complete FreeBSD system distribution (6 million lines of C code) on a 1GHz processor in 3 hours using 3.5GB of memory.
The CScout toolchest we implemented demonstrates how a family of C programs can be analyzed to support: simple refactorings, a one-to-one semantic mapping of the complete source to a relational database, a robust architecture-neutral obfuscated code distribution format, and the extraction of semantically-rich metrics with exact references to the original source code. The use of a general-purpose database schema for storing the source's semantic information, effectively isolates the analysis engine from the numerous transformations and metric extraction operations that can be performed on the source, providing flexibility, domain specificity, and efficiency.
The absence of a name clash error checking facility in the CScout refactoring browser can be a problem, but it is an attribute of the implementation and not an inherent shortcoming of our method. Early on we decided to dispose semantic information from memory once a scope had been processed so as to be able to handle software systems of a realistic size.
The CScout tools can process C, yacc and many popular C language extensions, but do not (yet) cover C++. Although the method clearly applies to C++, the effort to parse and semantically analyze C++ programs is an order of magnitude larger than the scope of the project we had planned. Furthermore, enhancing the refactoring browser or the database representation to cover some common object-oriented refactorings would be an even more complex task.
First of all the CScout tools should be able to parse and analyze other common languages such as C++, the lex program generator [37], and symbolic (assembly) code. Given that many projects automatically generate C code from specifications expressed in a domain specific language [31], we are currently experimenting with lightweight front ends that transform DSL programs into C code annotated with precise backreferences to the original DSL file. CScout will then be able to parse the synthetic code as C, but will display and modify the original DSL source code. Such capabilities will extend CScout's reach to a wider set of very large program families. In addition, the database schema used can be extended to separate code lines, and separately store and identify comments, strings, and, possibly, other constants. These last modifications will allow more sophisticated operations to be performed on the source code body employing a unified approach. Identifiers could also contain additional semantic information on their precise scope, type, as well as the structures and unions members belong to.
A related aspect of improvement concerns the integration with configuration and revision management tools. Large changes to source code bases, such as those that can be made by CScout, should be atomic operations. Although revision-control operations can currently be introduced into the modification sequence using a scripting language, a facility offering standardized hooks for specifying how the modifications are to be performed might be preferable.
Finally, the most ambitious extension concerns not the tool, but the theory behind its operation. Given that C/C++ code can now be directly modified in a limited way in its non-preprocessed form, it is surely worthwhile to examine what other larger refactoring operations can be safely performed using similar techniques. These would necessitate the marking of syntactic structure in the token sequences to allow rearrangements at the parse tree level. The effect the preprocessor facilities have on the representation of these structures, and methods that can mitigate these effects are currently open questions.
Dr. Spinellis is a member of the ACM, the IEEE, the Greek Computer Society, the Technical Chamber of Greece.
1 Department of Management Science and Technology, Athens University of Economics and Business, Patision 76, GR-104 34 Athina, Greece. email: dds@aueb.gr, phone: +30 2108203682, fax: +30 2108203685.