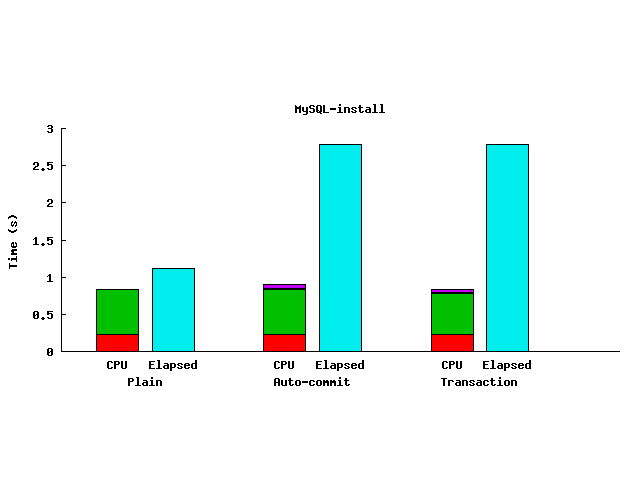
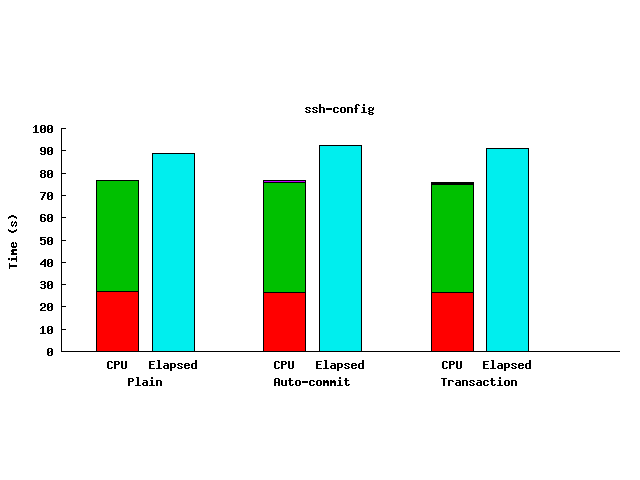
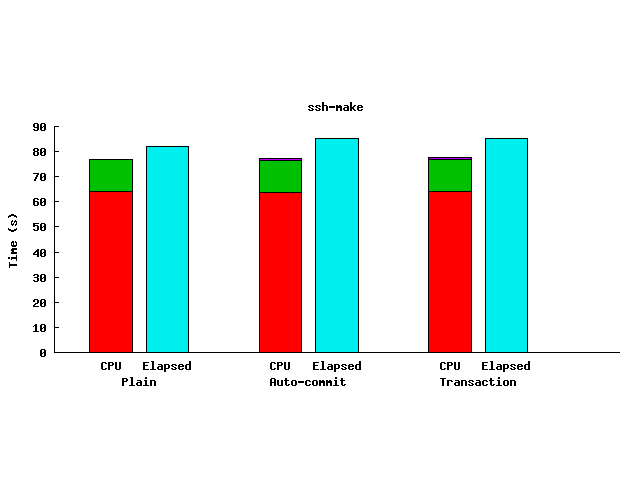
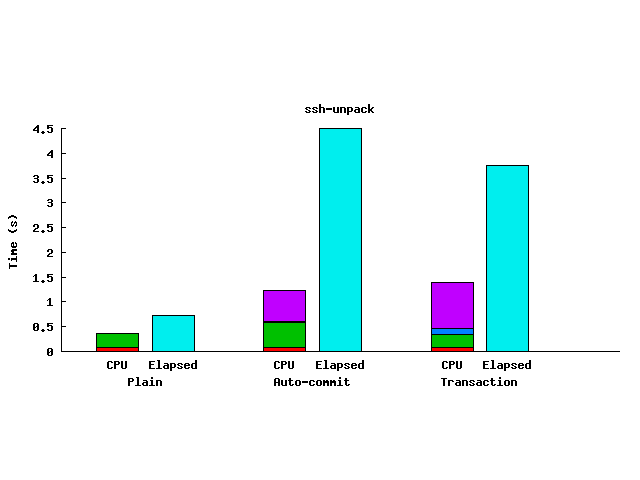|
Time | User Action | Transaction Logic | File System Changes |
|
12 | transaction begin | transaction id ← 1239; start_time ← 12 | create clone-1239 |
| 13 | touch a | commit_time[a] ← 13 (auto-commit) | |
| 14 | touch clone-1239/b | commit_time[b] ← 0 (pending commit) | |
| 15 | transaction begin | transaction id ← 1240; start_time ← 15 | create clone-1240 |
| 16 | transaction commit 1239 | OK (commit_time[b] < start_time) | copy clone-1239/b b |
| | commit_time[b] ← 16 | destroy clone-1239 |
| 17 | touch clone-1240/b | commit_time[b] = 16 (unchanged, pending commit) |
| 18 | touch c | commit_time[c] ← 18 (auto-commit) | |
| 19 | transaction begin | transaction id ← 1241; start_time ← 19 | create clone-1241 |
| 20 | transaction commit 1240 | Conflict (commit_time[b] > start_time) | destroy clone-1240 |
| 21 | touch clone-1241/c | commit_time[c] = 18 (unchanged, pending commit) |
| 22 | transaction commit 1241 | OK (commit_time[c] < start_time) | copy clone-1241/c c |
| | commit_time[c] ← 22 | destroy clone-1241 |
| 23 | transaction begin | transaction id ← 1242; start_time ← 23 | create clone-1242 |
| 24 | touch clone-1242/c | commit_time[c] = 22 (unchanged, pending commit) |
| 25 | touch c | commit_time[c] ← 25 (auto-commit) | |
| 26 | transaction commit 1242 | Conflict (commit_time[c] > start_time) | destroy clone-1242 |
|
|