 |
|
http://www.dmst.aueb.gr/dds/pubs/jrnl/1999-SIGPLAN-Optim/html/patop.html This is an HTML rendering of a working paper draft that led to a publication. The publication should always be cited in preference to this draft using the following reference:
|
Diomidis Spinellis
Department of Information & Communication Systems
University of the Aegean
GR-83200 Karlobasi, Greece
dspin@aegean.gr
Peephole optimisation as a last step of a compilation sequence capitalises on significant opportunities for removing low level code slackness left over by the code generation process. We have designed a peephole optimiser that operates using a declarative specification of the optimisations to be performed. The optimiser's implementation is based on string pattern matching using regular expressions. We used this approach to prototype an optimiser to convert target machine instruction sequences containing conditional execution of instructions inside loop bodies into code that adaptively executes the optimum branch instructions according to the program's branch behaviour.
Peephole optimization; branch prediction; regular expressions.
Peephole optimisation [ASU85, p. 554-558] as a last step of a compilation sequence capitalises on significant opportunities for removing low level code slackness left over by the code generation process. In addition, as peephole optimisers work on low level (target) code they can perform transformations based on specific characteristics of the target architecture. The declarative specification and implementation of the peephole optimisation process can offer a number of advantages over the procedural coding of the same specification:
The emergence of versatile text processing languages and high quality regular expression libraries has allowed us to experiment with a peephole optimiser design based on regular expression string pattern matching. In the following sections we describe a prototype implementation of a flow-of-control optimiser based on the declarative specification of optimisation patterns and their dynamic compilation into regular expression replacement sequences. We have used this optimiser to implement a software-based dynamic jump prediction scheme.
The remainder of this paper is structured as follows: Section 2 introduces the optimiser's design; Section 3 describes our motivating example based on a software-based dynamic branch prediction scheme, while Section 4 details the optimiser's implementation. The complete listing of the optimiser prototype implementation is provided as an Appendix.
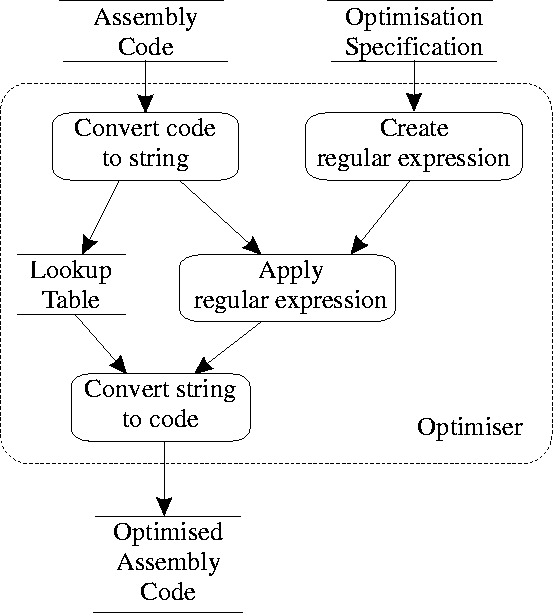
The optimiser's design is based on pattern matching [AG85] of the target code against declarative specifications as illustrated by the dataflow diagram in Figure 1. The optimiser initially converts the declarative -- domain specific [SG97] -- optimisation specification into a string regular expression that can be applied to an appropriate representation of the target code. As a trivial example Figure 2 contains a declarative optimisation specification for the elimination of jumps to jump instructions. The specification is written as a pattern to be recognised followed by the corresponding replacement code. The optimiser reads the target code, converts it into a string, storing relevant ancillary information into a lookup table, and then continuously applies the regular expression to the string representation of the target code performing the specified pattern-based substitutions. The repetitive nature of the regular expression application can result in higher order optimisations where the output code of one optimisation step is further optimised by the next application. Finally, the string representing the optimised target code is converted back into its normal representation based on the lookup table.
# Input pattern
jmpL1
S1*
L1: jmpL2
=>
# Output specification
jmpL2
S1*
L1: jmpL2
|
We tested the design of the optimiser using as a motivating example the optimisation of branch instructions. Modern processors make extensive use of overlapped instruction execution -- pipelining -- to increase their performance. This performance gain is not realised to its full potential due to the existence of hazards: conditions that prevent the execution of parallel instructions. Control hazards arise from the pipelining of instructions such as branches that change the program counter (PC). In this case the fetching and execution of instructions that follow a conditional branch instruction are stalled until the branch location is determined [HP90, p. 257]. It is possible to reduce pipeline stalls by predicting the program flow and arranging for the appropriate instructions to be fetched. In our example we use a loop code generation technique that results in code that adaptively follows a predicted branch path [Kra94].
Branch prediction methods can be broadly distinguished between static methods where the probable direction of program flow is determined before the program execution, and dynamic methods where branches are predicted during the program's execution by some measure of previous branch history [HP90, 307-314]. Static branch prediction methods compile branches assuming that a given branch will be taken or not taken according to various heuristics. The scheme can be improved by using profiling data from previous runs of the code [MH86, p. 401]. Dynamic schemes depend on hardware memory which is used to store the behaviour of branch instructions in their previous executions. Given the finite amount of storage that can be used to store the behaviour of all branch instructions in a program, hashing and LRU-buffer techniques are used to store predictions about a subset of the branch instructions [Smi81]. In the case of branches that are usually not taken a one-bit prediction scheme will result in two wrong guesses when a branch is taken. In order to avoid this situation an additional bit can be used to provide a second order prediction behaviour. A branch prediction buffer can be further extended into a branch target buffer by storing in the buffer the actual branch target instruction, thus gaining an instruction fetch cycle. A comparison of software and hardware schemes for reducing the cost of branches can be found in [HCC89].
Instruction sequences containing conditional execution of instructions
inside loop bodies can be compiled into code that adaptively executes
the optimum branch instructions according to the program's branch
behaviour.
A loop body containing an if-then-else conditional statement is
compiled into two loop sequences: one sequence compiled for optimum
behaviour when the then branch is taken, and one compiled for
optimum behaviour when the else branch taken.
For both sequences the code body for the part which is predicted
not to be executed is replaced with a branch to the corresponding code of the
other sequence.
Thus, the code in Figure 3
is compiled using branches with a high taken penalty as shown
in Figure 4.
The technique is applicable to many different loop code sequences
containing conditional branches.
LOOP
statement-1
IF condition THEN
statement-2
ELSE
statement-3
FI
statement-4
END LOOP
|
L1: statement-1
test condition
branch if not condition L4
L2: statement-2
statement-4
branch L1
L3: statement-1
test condition
branch if condition L2
L4: statement-3
statement-4
branch L3
|
In order to test out our approach we implemented a prototype optimiser and used it to implement the dynamic branch prediction scheme described above.
The optimiser first reads the compiler's target language output and converts all lines into strings composed of three token classes:
S0025 L0000: S0026 S0027 jeL0001 S0028 jmpL0002 S0029 L0001: S0030 L0002: S0031 jmpL0000 S0032 S0033 S0034 S0035
The optimiser then reads the declarative specification of the optimisations to be performed. Figure 5 contains the optimisation specification for the one-bit loop optimisation presented in Section 3.2. The specification is written as a pattern to be recognised and the replacement code.
The pattern to be recognised can consist of:
# Input pattern
L1:
S1*
jeL2
S2*
jmpL3
S5*
L2:
S3*
L3:
S4*
jmpL1
=>
# Output specification
N1:
S1
je N2
N4:
S2
S4
jmp N1
N3:
S1
jne N4
N2:
S3
S4
jmp N3
|
The replacement text is separated from the code pattern by a `=>' symbol and consists of:
The input pattern is converted into an extended string regular expression with the appropriate tokens replaced with back-references to the tokens in the previous part of the expression. Thus the pattern specification in Figure 5 is translated into the following regular expression ( means any number of digits and number is a back-reference to a previous bracketed expression):
(L\d+):(S\d+)*je(L\d+)(S\d+)*jmp(L\d+) (S\d+)*\3:(S\d+)*\5:(S\d+)*jmp\1
the corresponding replacement specification ($number is a reference to a bracketed part of the regular expression):
$N1: $2
je $N2
$N4: $4
$8
jmp $N1
$N3: $2
jne $N4
$N2: $7
$8
jmp $N3
and code to increment the label variables $N.
The optimiser works by continuously matching the input regular expressions against the tokenised program and replacing the matched part with the specified output code. When no more matches can be performed the tokenised program is converted back into normal target code using the lookup table built in the first phase to derive the optimised target code.
The declarative specification of the optimisation operations, and the use of string regular expressions for code pattern matching resulted in a flexible and compact implementation. The optimiser is currently a 127 line program written in Perl [SCP96]. It has been tested on Intel iAPX86 assembly output generated by the Microsoft C compiler.
So far the approach and the optimiser have only been tested on small example programs, a single optimisation specification, and a limited number of flow-of-control optimisations. However, the modest implementation effort invested and the flexibility offered by the parametric, declarative specification of the optimisation operations convinced us that this approach can be particularly suitable for rapid prototyping and experimentation with new optimisation methods, novel target architectures such as the Java VM, and applications of higher order optimisations.
# Optimise a program with branches based on a
# declarative specification
($#ARGV == 1) || die "usage: $0 rules code\n";
strprog($ARGV[1]);
mksubst($ARGV[0]);
print "subst=$subst\n" if ($debug);
eval($subst);
$_ = $prog;
unstrprog();
print;
# Convert the change specification into the
# regular expression substitution program $subst
sub mksubst
{
my($in) = @_;
open(IN, $in) || die "$in: $!\n";
for ($i = 0; $i < 10; $i++) {
$subst .= "\$N$i = \"\\\$BO${i}0000\";\n";
}
$n = 1;
$subst .= 'while ($prog =~ s/';
while (<IN>) {
last if (/^\=\>/);
next if (/^#/);
chop;
if (m/(([LS])\d+)/) {
$name = $1;
$type = $2;
if ($new = $pre{$name}) {
$new =~ s/\$/\\/;
s/$name/$new/;
} else {
$pre{$name} = "\$$n";
$n++;
s/$name/($type\\d+)/;
}
s/\s+//g;
}
$subst .= $_;
}
$subst .= '/';
undef %N;
while (<IN>) {
next if (/^#/);
if (s/(N(\d+))/\$$1/) {
$N{$2} = 1;
}
if (m/(([LS])\d+)/) {
$name = $1;
if (!$pre{$name}) {
printf STDERR "Unknown replace name $name\n";
exit (1);
}
s/$name/$pre{$name}/;
}
$subst .= $_;
}
$subst .= "/g) {\n";
foreach $i (keys %N) {
$subst .= "\t\t\$N$i++;\n";
}
$subst .= "
}
";
}
# Convert program into the string $prog
sub strprog
{
my($in) = @_;
open(IN, $in) || die "$in: $!\n";
$S = $L = 0;
$s = $l = '0000';
while (<IN>) {
# $L{internal} = program
# $l{program} = internal
# labels (start with a $)
if (m/(\$\w+)/) {
$name = $1;
if ($old = $l{$name}) {
$name =~ s/([^\w])/\\$1/g;
s/$name/$old/e;
} else {
$new = $l{$name} = "L$l";
$L{"L$l"} = $name;
$name =~ s/([^\w])/\\$1/g;
s/$name/$new/;
$L++;
$l = sprintf('%04d', $L);
}
}
# Skip branches (start with j) and
# labels (end with :)
if (m/^\tj/ || m/:$/) {
chop;
s/SHORT//;
s/\s+//g;
} else {
# Other statements
$name = $_;
$new = $s{$name} = "S$s";
$S{"S$s"} = $name;
$_ = $new;
$S++;
$s = sprintf('%04d', $S);
}
$prog .= $_;
}
}
# Convert $_ back to the original program
sub unstrprog
{
while (m/(L\d+)/) {
$name = $1;
s/$name/$L{$name}/;
}
while (m/(S\d+)/) {
$name = $1;
s/$name/$S{$name}/;
}
}