|
http://www.dmst.aueb.gr/dds/pubs/jrnl/2005-IR-PDI/html/Spi04b.html This is an HTML rendering of a working paper draft that led to a publication. The publication should always be cited in preference to this draft using the following reference:
|
``Users should beware that there is no general guarantee that a URL which at one time points to a given object continues to do so, and does not even at some later time point to a different object due to the movement of objects on servers.''- T. Berners-Lee et al. Uniform Resource Locators (URL). RFC 1738.
The dynamic nature of the web-Chankhunthod et al. [CDN+96] report the average lifetime of an HTML text object to be 75 days-results in URLs that quickly decay and become inaccessible [Pit99,Ash00]. According to our earlier work [Spi03] around 27% of the URLs referenced in IEEE Computer and the Communications of the ACM articles from 1995-2000 were no longer accessible at the end of the period. In addition, after four years almost 50% of the referenced URLs are inaccessible. Lawrence et al. [LPF+01] have identified similar trends for published URLs. A number of solutions have been proposed for handling this link integrity or referential integrity problem. The solution classes that have been identified [Ash00] include prohibiting change, maintaining document versions, regularly updating all links, aliasing a link's end points, posting notifications of changes to document locations, implementing forwarding mechanisms, automatically detecting and correcting broken links, and creating all links dynamically. For links to published papers citation linking [HCH+99], provided as a service by publishers or public-service efforts [LGB99], may lead to publication formats that actively support hypertext links across time.
Although URNs, PURLs and the Handle mechanism may offer a long-term solution, they have up to now not been universally adopted. Thus, individual user bookmarks and publicly distributed URLs quickly become obsolete as documents change names, directories, or are hosted on different places. Although a search engine [LG99,Tak00] can be used to relocate a document after a web server's ``404-document not found'' response, this is a tedious and error-prone procedure. In this paper we describe a way to automate the searching task by providing a more persistent alternative to a URL. Such an alternative can be used both to provide page bookmarks that are relatively immune to URL changes and as a centralized, alternative method for creating URNs without the active cooperation of the content creators.
Our scheme involves having a search engine calculate for every URL an augmented, persistent version. The augmented URL, containing the original URL and words that uniquely identify the document, will have a high probability to locate the original document even if its contents have changed location. Users who save the persistent URL to bookmark a page can later transparently retrieve the document through a search engine's infrastructure. If the default document retrieval mechanism fails, the search engine will resolve the URL by searching for documents containing the words embedded in the URL. In addition, web sites can use persistent URLs to point to pages outside their administrative domain with a lower probability that these links will become unavailable when the respective page contents change location. As an example, given the URL http://moving.org/target whose contents could be uniquely identified by the words gloxinia and obelisk the corresponding persistent URL would be of the form: http://resolve.com/find?orig=http://moving.org/target&w=gloxinia+obelisk (to make the example clearer we have not URL-encoded the original URL). When the user tries to access the above URL the search engine infrastructure at resolve.com will first try to retrieve the document at http://moving.org/target. If that fails, it will search its (up to date) index for a document containing the words gloxinia and obelisk. If one of the two above actions succeeds the user will be redirected to the document's original or revised location, otherwise a ``404 Not found'' error will be returned.
The remainder of this paper outlines the current process of document retrieval and the associated errors (Section 2), describes our algorithm for calculating unique document discriminants (Section 3), and sketches a prototype implementation of the concept (Section 4). In Section 5 we discuss the method's performance in terms of retrieval accuracy, time and space requirements, and scalability. The paper concludes with a presentation of possible extensions and applications of our technique.
//<user>:<password>@<host>:<port>/<url-path>
The double slash indicates that the scheme data complies with the Internet scheme syntax. The host is specified using the fully qualified domain name of a network host or its IP address. The default port for the HTTP scheme is 80 and is usually omitted.
For a web page of a given URL to appear on a browser's screen a number of different technologies and protocols must work in concert. In addition, the changing realities of the web and the Internet have vastly complicated the simple end-to-end request-reply protocol that used to form the basis of the early HTTP transactions. Any failure along the complicated chain of actions needed to retrieve a web page will lead to a failed URL reference.
The path appearing in a URL will nowadays not necessarily match with a corresponding local file on the server. Web servers provide a number of mechanisms for managing namespaces. Some of them are: the creation of a separate namespace for every local user, the definition of protection domains and access mechanisms, the support of aliases to map namespaces to local directories, and the dynamic creation of content using technologies such the common gateway interface (CGI), servlets, and server-modified pages (ASP, JSP, PSP). In addition, a feature of the HTTP protocol called content negotiation allows a server to provide different pages based on technical or cultural characteristics of the incoming request (e.g. bandwidth, display technology, languages the user can understand).
The HTTP protocol defines 24 different errors that can occur within an HTTP exchange. In addition, some errors can occur before the client and server get a chance to communicate. In practice, while verifying thousands of published URLs we encountered the following errors:
Not all of the above problems can be solved by the provision of persistent URLs. A persistent URL will help in cases where the original document has changed its name (including the path to its name) resulting in a ``404 Not found'' error, and in cases where the domain hosting the URL is renamed resulting in a ``901 Host lookup failure'' error. Changes in a document's access authorization are not a technical but a legal problem, while the 500-class server errors are more appropriately handled by a robust network infrastructure and mechanisms such as proxies, mirrors, archives, and content delivery networks. In addition, persistent URLs can not deal with documents that are deleted or modified, unless the corresponding URLs are designed to work in concert with an appropriate archive repository.
The computing infrastructure of a large search engine is ideally placed to efficiently perform both the calculation of the persistent URLs and their resolution. These two can then be provided as an extra service to the engine's users. In addition, the search engine will draw additional traffic (and potentially advertising revenues) each time a user accesses a bookmarked persistent URL or follows such a URL on the web.
The persistent URLs will most likely be less easy to remember than the URLs they are derived from. However, these URLs will be primarily stored as bookmarks and hyperlinks and automatically processed, rather than memorized and communicated by humans. For this reason, it is not necessary to use natural terms for searching; any terms that uniquely identify the document are suitable for this purpose.
The idea of locating documents by words those documents contain is not novel. Phelps and Wilensky [PW00] proposed the construction of robust hyperlinks by means of the similarly working lexical signatures and suggested a heuristic technique for calculating the signatures. Specifically, their method involves using terms that are rare in the web (have a high inverse document frequency-IDF), while also favoring terms with a high term frequency (TF) within the document, capping TF at 5 to avoid diluting a term's rarity. The IDF of each term is derived from a search engine, while the rest of the signature calculation can be performed locally. Park et al. [PPGK02] expanded on this idea by evaluating four basic and four hybrid lexical signature selection methods based on the TF, document frequency-DF, and IDF of those terms. For example, one of their proposed methods TFIDF3DF2 involves selecting two words based on increasing DF order, filtering out words having a DF value of one, and selecting three additional words maximizing TIFF. An important contribution of their work is an evaluation of the documents that the search engine returns in response to a lexical signature query in terms of uniqueness, appearance of the desired document at the top of the result list, and relevance of any other document links returned.
Our approach differs from the two methods we outlined in that it uses the search engine as an oracle for evaluating the selected word set. A stochastic algorithm can rapidly explore the search space (word combinations) to locate the ones that better suit a selection criterion. This allows us, instead of having a fixed algorithm (such TFIDF3DF2) identifying a document's discriminants, to flexibly select from each document the discriminant that maximizes an objective function. Although the objective function we used is based on uniqueness and URL length, different functions such as the relevance of the returned documents could also be used.
|
An efficient deterministic solution to the problem would be preferable to the exhaustive search we outlined above. However, as we will show in the following paragraphs, the problem is intractable, NP-complete.
|
Similarly, the subset sum problem can be expressed as follows: Let A = {a1, ..., an} be a set of positive integers. Given an integer s find a set A� � A with m = |A�| so that
|
If the n elements of the set A have values 0 ... m we can solve the subset sum problem in terms of the discriminant cardinality problem by using set intersection in the place of addition. For each element ai � A we construct a set
|
|
|
|
GAs base their operation on a fitness function that evaluates an organism's suitability. The fitness function [`O](x) we want to maximize depends inversely on the number of documents ND a particular discriminant x identifies and, less, on its length L as determined by the number of words NW and the length of each word Li:
|
An important characteristic of a genetic algorithm's implementation concerns the representation of each candidate solution. A good representation should ensure that the application of standard crossover recombination operators (where a new organism is composed from parts of two existing ones) will result in a valid new representation. The first organism implementation we used was an ordered set of terms. Thus, for a document containing the words [A B C D E F] two organisms could be [A C F] and [B E]. Following experimentation, we found that a boolean vector sized to represent all possible terms of a document-with discriminant terms represented by true values-was a more efficient implementation allowing our code to function in a third of the original runtime. Using a boolean vector scheme, the two above organisms would now be represented as [T F T F F T] and [F T F F T F].
Using the integers 0 and 1 for representing the true and false boolean values, the genetic algorithm for selecting the minimal unique discriminant out of N different terms can be described in the following steps:
The implementation of genetic algorithms can be tuned using a number of different parameters. In our implementation we used the parameters that Grefenstette [Gre86] derived using meta-search techniques namely:
The random floating point numbers 0 < R < 1 used for selecting the crossover points, the mutation rates, and the selection of organisms were produced using the subtractive method algorithm [Knu81].
In addition we used some domain-specific heuristics:
All the above heuristics are based on the premise that less frequently used terms are more likely to be part of a unique document discriminant.
As usual the devil is in the details, especially when dealing with the 1 million documents we processed and the 3 ·109 documents currently indexed by typical search engines.
Our application consists of tools for calculating unique discriminants on a single node (useful for proving the concept, trying out the data subset, and experimenting with the algorithms), and in an environment of multiple nodes (for processing the data set of a commercial search engine). In addition, we implemented simple tools for querying the results and obtaining the corresponding URLs.
We handled the problem by accumulating a term-to-document index in memory and monitoring the memory subsystem's performance. Once the system begins to persistently page (indicating that the memory's capacity has been reached and performance will rapidly degrade due to thrashing), the index is flushed to disk as a sorted file. When all documents have been processed, the partial results are merged into a single file (idxdata) containing terms and documents where each term occurs. An index file (idxdata.idx) allows rapid serial access to individual terms without having to traverse a term's document list. In addition, a separate file (idxdata.hash) allows rapid hash-code based access to individual terms. As the string hash function, we use the one recently proposed for very large collections by Zobel [ZHW01]. The hash file is created after the merge phase and can thus be optimally sized, using the Rabin-Miller prime number probabilistic algorithm [Sch96], to minimize collisions.
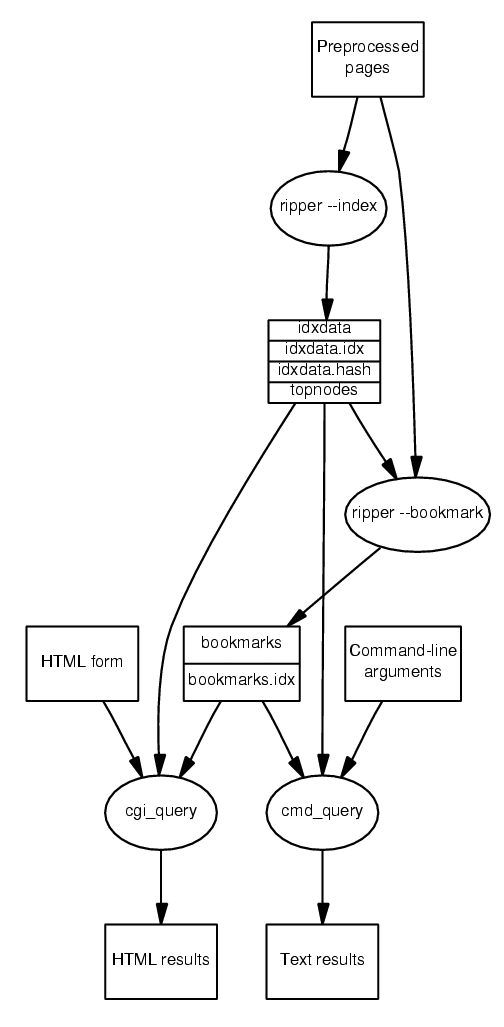
The data-flow diagram of our system's stand-alone operation appears in Figure 1. A new handler of the Google ripper named index reads-in preparsed documents and creates (in stages by merging intermediate results) an index of the documents where each term resides (idxdata) and two files for accessing that index (idxdata.idx and idxdata.hash). A fourth file, topnodes is set to contain the frequencies of the 100,000 most frequently used terms; it is used as a cache during the discriminant calculation phase.
The second phase is also implemented as a separate ripper handler named bookmark. This reads the terms of each document, selects the least frequently used ones, and creates the bookmarks file containing for each document its URL and the set of terms forming its unique discriminant. The bookmark.idx file created allows the location of a given document URL and discriminant based on the corresponding document identifier.
Two query programs we wrote, cgi_query and cmd_query, will search the term index against the conjunction of a set of specified words and display as search results the matching document URLs and the corresponding unique discriminants. The CGI application presents the discriminants as a URL; the end-user can bookmark this URL and thus visit our search engine to locate the document in the future. The HTML results also contain a link to a Google search with the same discriminant as a search expression. This search will not in general provide unique results since Google's indexed collection is three orders of magnitude larger than the one we processed. One of the discriminants we tried did however identify and correctly locate one page that was moved (renamed): a Google search for the page http://www.umass.edu/research/ogca/new.htm uniquely identified through the discriminant ``ogca fy02'' now yields http://www.umass.edu/research/ogca/news/oldnews.htm.
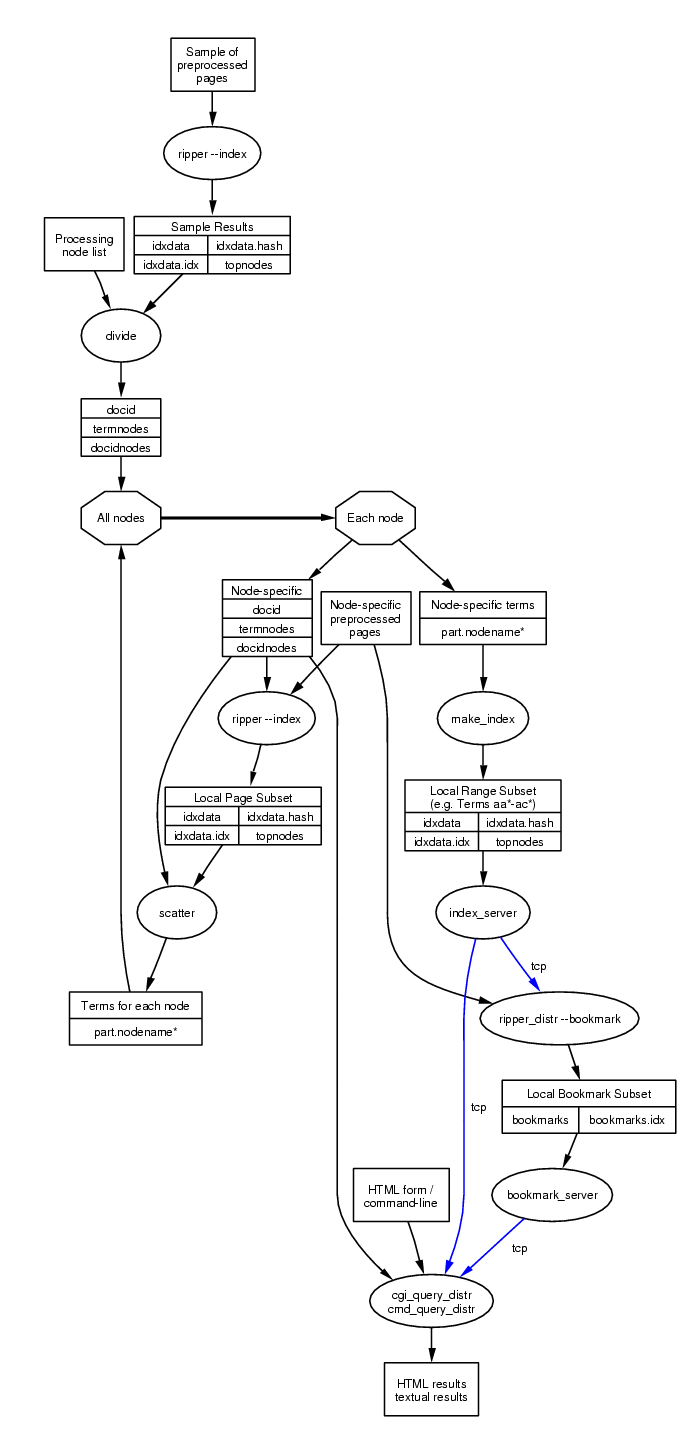
As is apparent from Figure 2, the system's distributed operation is a lot more complicated than the stand-alone case. It does however provide a framework for creating discriminants for orders of magnitude larger collections using a large number of commodity processing nodes. The work distribution strategy is based on two premises:
To divide the term load across the nodes, we run a stand-alone instance of ripper --index on a small representative subset of documents. A separate text file contains a list of all processing nodes. The program divide:
assigns a separate numeric initial document-id to each node, and
copies the generated files to all nodes.
On each node we then run an instance of ripper --index to process the node-specific preprocessed pages. The program scatter is then run on each node to split and copy the resulting term index according to the terms assigned to each node. Each node will thus receive its share of terms as indexed by all other nodes. The make_index program merges the node-specific terms generated by all nodes into a single unified index file for the given node. This file is accessed by the node's index_server program to provide term document occurrences to other nodes. The ripper_distr program run on each node communicates with the index_server responsible for a given term to obtain the global list of a term's documents. To reduce network communication overhead initial term frequencies (our algorithm uses a subset of a document's least frequently occurring terms for selecting the unique discriminant) are obtained from the local term file; we assume that the local term frequency distribution corresponds to the global one. The generated unique document discriminants can then be accessed by the distributed versions of the query programs by using a document's identification number for locating the node where the respective discriminant is used.
| Number of terms | # documents | Document % |
| 0 (no discriminant found) | 5,107 | 0.56 |
| 1 | 531,713 | 58.02 |
| 2 | 331,638 | 36.19 |
| 3 | 41,132 | 4.49 |
| 4 | 5,956 | 0.65 |
| 5 | 783 | 0.08 |
| 6 | 80 | 0.01 |
| 7 | 16 | 0.00 |
| 8 | 3 | 0.00 |
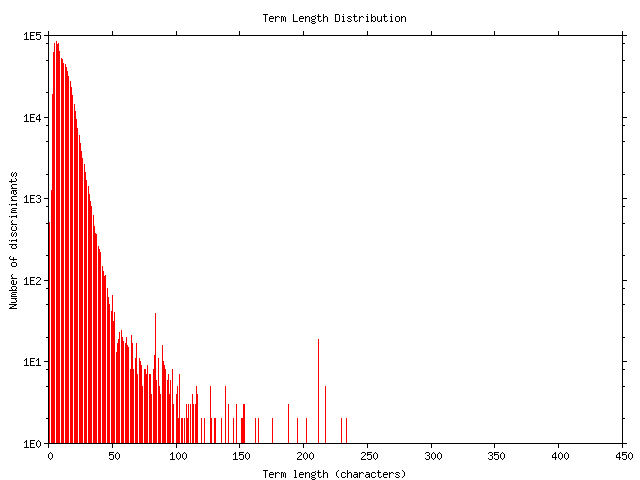
After processing the Google sample document collection we found that we needed an average of 1.47 terms to uniquely identify a document. The average length of each discriminant (Figure 3) was 10.77 characters which, as a document identifier, compares extremely favorably with the 43.9 characters of the collection's average document URL length (excluding the initial http://. The number of terms for each document's discriminant was distributed as shown in Table 1. The algorithm failed to identify a discriminant for less than 1% of the documents processed.
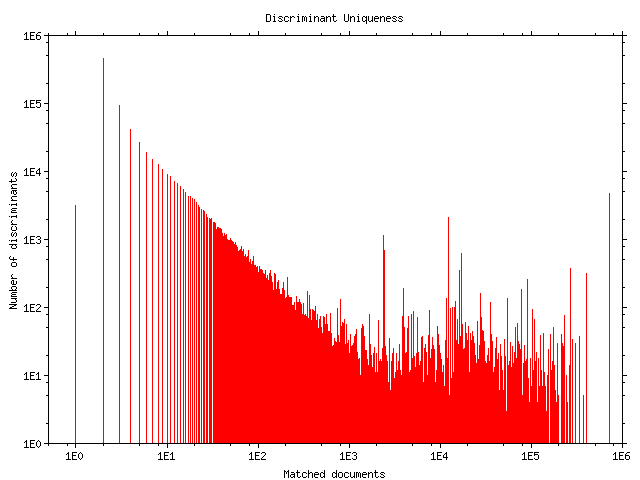
The property of the calculated discriminants to uniquely identify a document, while not absolute, was we believe acceptable for its intended uses. About 50% of the discriminants our system calculated will locate a single document, while another 10% identify two documents. In total 76% of the discriminants will locate less than 10 documents in the sample document collection (Figure 4). These figures can be further improved by tuning various GA parameters such as the number of terms of the candidate set, the number of common terms to eliminate, and the size of the organism pool. Many of the pages for which a unique identifier was not calculated contain very little textual material. As an example our system's spectacular failure to create a unique identifier for the page http://humanities.uchicago.edu/depts/maph/ (it was identified by the term `humanities', which also matches another 29,497 pages) can be easily explained by the fact that this home page consisted entirely of text and pictures presented in graphical hypertext form using image maps.
The time to perform the unique discriminant calculations varied, because we split the workload among 20 different machines. The time required on 733MHz, Celeron CPU, IDE disk machine for processing the file pprepos.00 (16,564 documents) was 58,721 real, 184,054 user, and 9,604 system seconds giving a processing time of 3.54 s / document. Systems with a SCSI disk subsystem performed better.
We unfortunately lacked appropriate resources (a large farm of networked processing nodes of similar technical characteristics) to perform rigorous experiments on the distributed implementation of our system. We were however able to obtain a lower bound of the expected performance by running the programs on a small number of workstations. By extrapolating from our results, we calculated the expected distributed operation time T� given a standalone time of T as T� � T ×2.2.
The space requirements of the discriminant calculation phase are more difficult to judge. When performing calculations over the sample collection we observed a maximum resident set size 62,140KB. This number is likely to grow with a larger document set, but not by much, since it reflects the space needed to store the document instances of a document's least frequent terms. Given that prior to the candidate set selection, only term frequencies are stored in memory, the term selection process can be easily adjusted to dynamically select terms that will load in the main memory a fixed number of document occurrences, thereby providing a concrete bound to the memory usage.
Computing the term index will therefore require:
|
|
The time to compute the discriminants will be larger. At 3.54 s / document the calculation of all discriminants will require
|
Note that all our time figures are based on the results we obtained using low-end 733MHz Celeron PCs with IDE hard disks. In addition, the indexing phase can be omitted and the discriminant calculation phase can be easily adjusted to use a search engine's existing term index structure. The discriminant calculation algorithm only needs access to an oracle that answers the question of how many documents are matched by a given term combination. We assume that a search engine's infrastructure is engineered and tuned to efficiently answer the above query and should therefore preferably be used by our algorithm.
However, the document identifiers we provide are not suitable as universal replacements for the URLs currently employed. In document retrieval terms their use involves a trade-off of noise over silence. Our calculation method is not perfect and there are cases where our algorithms will either fail to calculate a discriminant for a web page (e.g. when the page does not contain any text), or will calculate a discriminant that will match multiple pages. In addition, changes to the web contents and a search engine's coverage can make identifiers that were calculated to be unique match additional documents. Although we have not studied the temporal behavior of the discriminants we calculate, an obvious pathological case involves documents cloned from a given source document through small additions or changes. This cloning is a common operation and is related to the scale-free topology of the web [BAJ00]. Cloned documents will very probably match the discriminant calculated for their original ancestor. Based on the above, we believe that unique discriminants are most suited for situations where a human can make an informed choice for using them and remains in the loop during their use. As an example, personal bookmarks are particularly well suited for being stored using unique discriminants (or include unique discriminants as a fail over mechanism). Bookmarks are highly prone to aging since they are typically not formally maintained; in addition, once a bookmark matching several documents is followed, the user can intelligently choose between the different pages.
During our work, we noted a number of improvements that could be employed for optimizing the algorithm's performance and for further increasing the usefulness of the obtained results. These include:
Associate with each URL and discriminant a unique multi-byte hash code that will accurately identify the precise location of pages that have not moved.
We end our description, by noting how the realization of the application we outlined was made possible only through the combination of multiple computer science disciplines: information retrieval was the domain where our problem was formulated, algorithms and data structures provided the framework to obtain the solution, operating system concepts allowed us to bound the indexing memory requirements, complexity theory gave us the theoretical background for searching for algorithmic solutions, stochastic approaches were used for sidestepping the problem's NPC characteristics, and networking and distributed systems technology provided the framework for developing the distributed implementation. Increasingly, the immense scale of the web is necessitating the use of multidisciplinary approaches to tackle information retrieval problems.
1 Address: Patision 76, GR-104 34 Athina, Greece. email: dds@aueb.gr